


就在昨天,谷歌正式发布了 Gemma 4。这次更新在 AI 圈引发了巨大轰动,它不仅主打“本地化运行”,更是在小参数规模下实现了惊人的“全模态”处理能力。
💎 一、 版本划分:从手机到工作站全覆盖
谷歌此次推出了 4 个版本,精准匹配不同硬件场景:
1. 轻量化系列(移动端 / IoT)
版本: 2B(20亿参数) / 4B(40亿参数)
亮点: 极低延迟,针对手机、边缘设备优化,重点强化了多模态感知。
2. 高性能系列(本地 GPU / 工作站)
版本: 26B(MoE 专家混合模型) / 31B(Dense 稠密模型)
亮点: 支持复杂逻辑推理,完全胜任编程助手、智能 Agent 系统,支持 100% 离线运行。
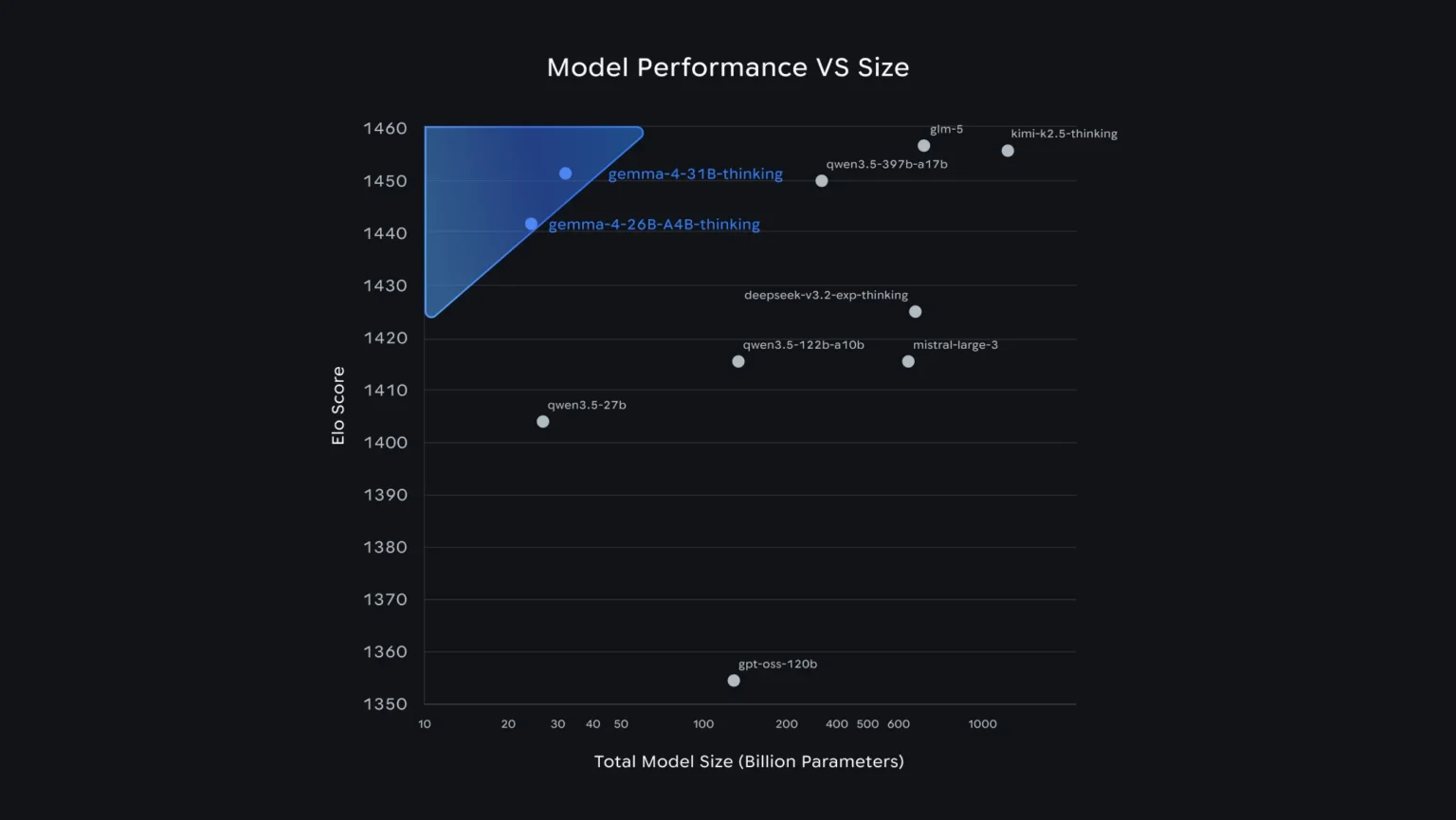
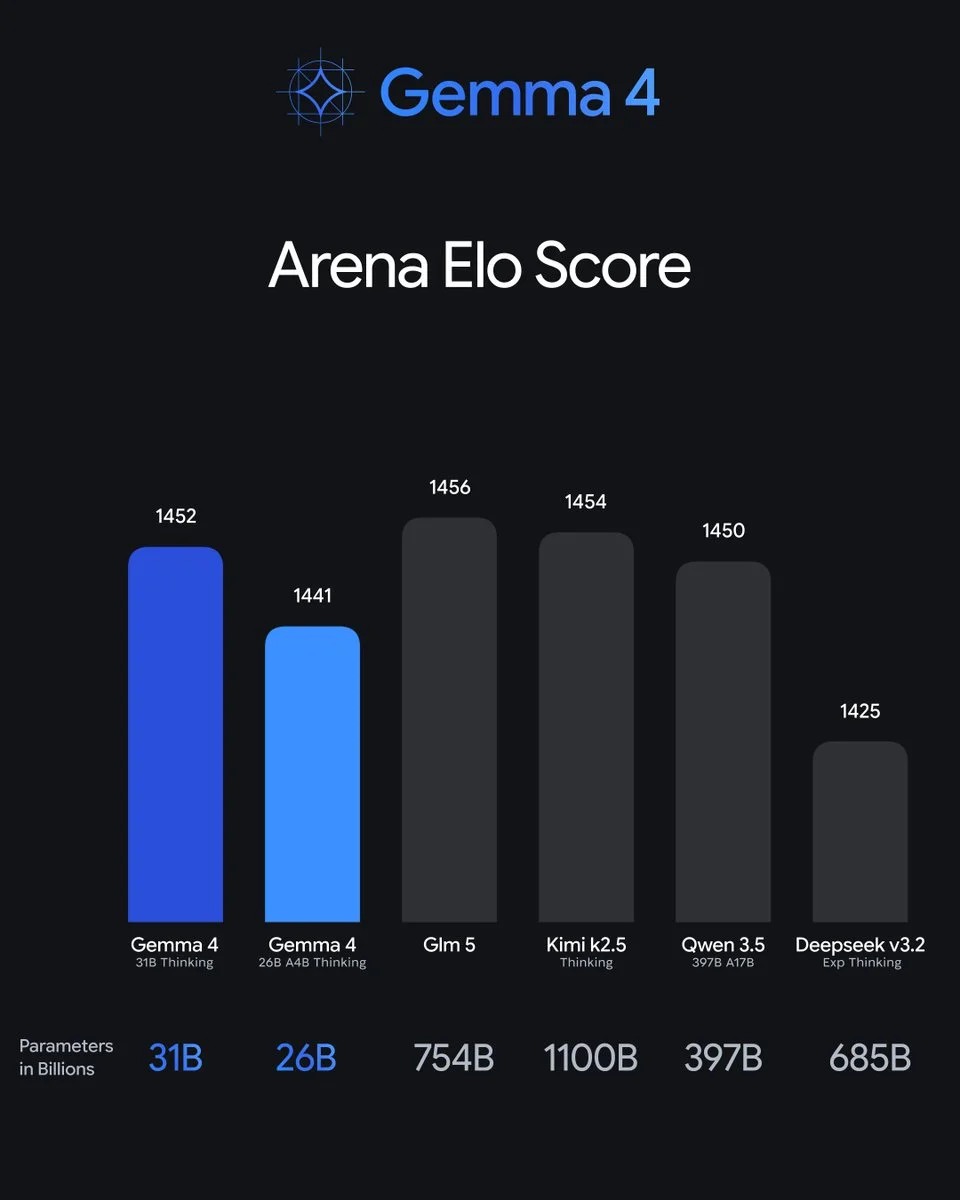
📊 二、 性能对比:效率之王
在 Arena-Hard 排行榜中,Gemma 4 的表现令人惊叹:
31B 版本: 稳居 Top 3
26B 版本: 位列 Top 6
结论: 谷歌通过架构优化实现了“小模型干大事”,其单位参数的智商水平甚至超越了部分体积大其 20 倍的巨型模型。
🛠️ 三、 核心全能特性
Gemma 4 不仅仅是一个对话模型,它是一个全能 AI 系统:
👁️ 多模态能力: 原生支持 OCR 图像识别、视频内容理解及音频直输。
💻 顶级编程: 擅长离线代码生成、Web 开发及自动构建 Docker 配置。
🤖 进化版 Agent: 支持复杂的工具调用(Function Calling)与工作流自动化。
🌍 全球化支持: 适配 140+ 种语言。
🛡️ 隐私至上: 数据不上传云端,完美契合企业私有化部署及个人隐私需求。
📜 四、 开源协议(开发者利好)
Gemma 4 采用 Apache 2.0 协议:
✅ 完全免费商用
✅ 允许任意修改与二次开发
✅ 支持私有化部署
💻 五、 硬件配置指南
根据你的显存(VRAM)选择最合适的版本:
🚀 六、 快速部署教程
第一步:安装基础环境
下载并安装 Ollama(支持 Windows/Mac/Linux)。【下载 Ollama】

进入官网下载安装(支持):
在终端执行安装指令:
Bash
ollama run gemma4
第二步:对接 OpenClaw (小龙虾)
以管理员身份运行 PowerShell:
PowerShell
# 安装 OpenClaw
irm https://openclaw.ai/install.ps1 | iex
# 启动对接
ollama launch openclaw
第三步:联动 Claude Code
根据系统执行安装命令:
Windows:
curl -fsSL [https://claude.ai/install.cmd](https://claude.ai/install.cmd) -o install.cmd && install.cmdMac/Linux:
curl -fsSL [https://claude.ai/install.sh](https://claude.ai/install.sh) | bash运行:
ollama launch claude
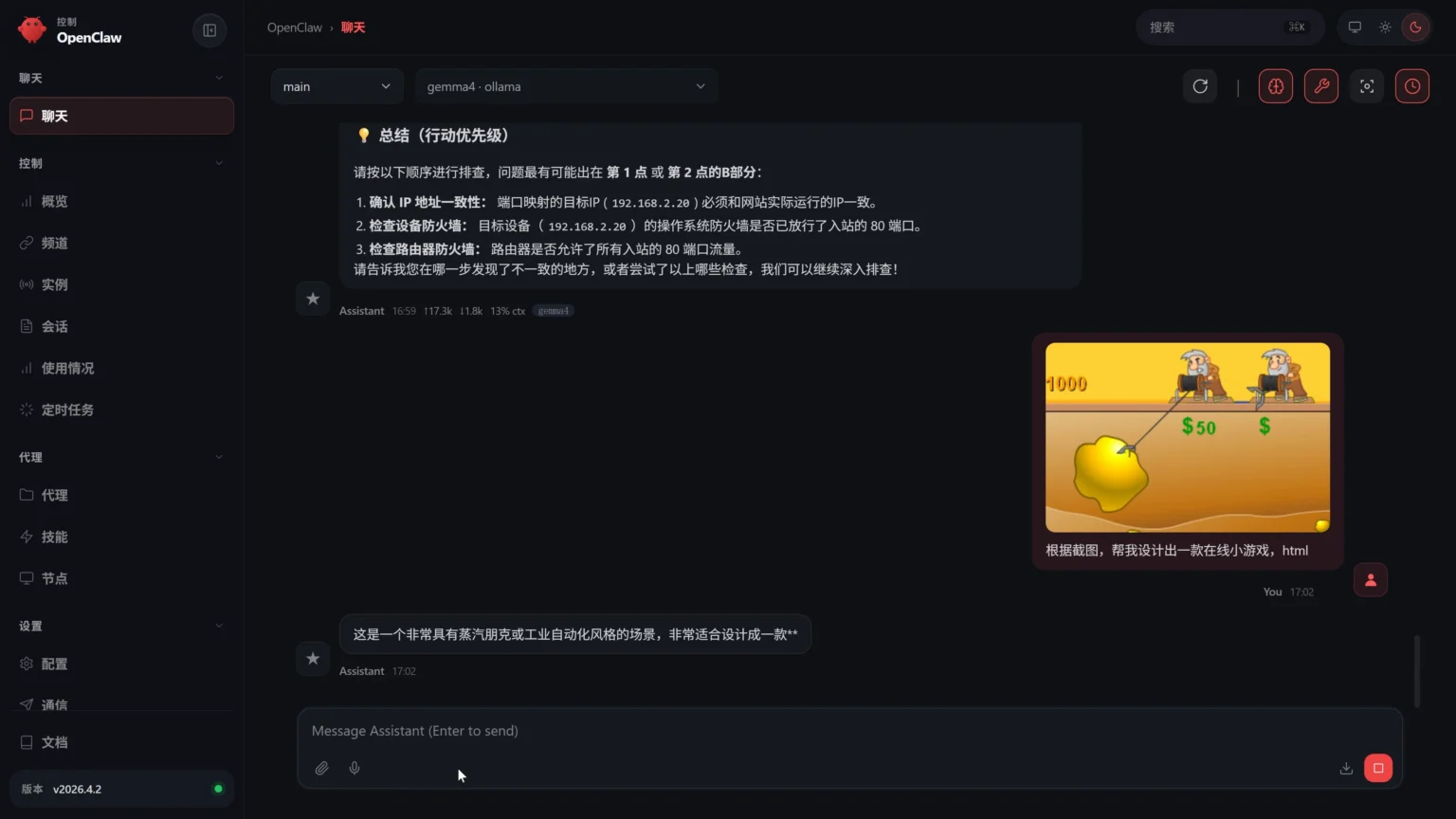
🌟 七、 实测亮点展示
网络排障: 能够逻辑严密地分析端口映射失败原因,并给出针对性方案。
看图绘模: 上传一张系统架构图,模型可直接生成对应的 Docker Compose 脚本。
视觉转游戏: 仅凭一张游戏截图,即可编写出具备核心逻辑的可运行小游戏。
自动化生产: 配合 Agent 工具,可实现从“抓取新闻”到“翻译”再到“生成 Markdown 博客”的全自动流程。
💡 八、 使用建议
不要盲目追求大参数: 如果显存不足,运行 31B 会导致严重的卡顿。24GB 显存用户建议优先选择 26B 或 31B 的量化版。
离线优势: 在断网环境下,Gemma 4 依然能提供稳定的生产力输出。
总结: Gemma 4 的出现标志着开源 AI 步入了“全模态+高逻辑”的新纪元。如果你需要一个私密、强大且能干脏活累活的 AI 助手,现在就是部署的最佳时机。


评论区