


如果你正在寻找一套既能保护隐私、又能实现“无限 Token”消耗的 AI 工作流,那么 Hermes Agent + Qwen3.6 的组合是当下的不二之选。无论是辅助代码编写、逻辑推理,还是自动化处理繁琐任务,这套本地方案都能提供近乎零延迟的专业体验。
为什么选择这个组合?
真正的 Token 自由: 无需订阅,不计流量,本地硬件跑多久,AI 就陪你多久。
隐私堡垒: 数据不上传云端,对于涉及敏感硬件架构(如 SATA 方案、FPGA 逻辑)的开发极其友好。
Agent 赋能: Hermes 不仅仅是一个聊天框,它赋予了 AI 执行自动化任务的能力。
🛠 部署全流程指南
第一步:环境基石 —— WSL2 与 GPU 直通
在 Windows 下,WSL2 是运行 Linux 环境的最优解。
安装 WSL: 管理员模式运行 PowerShell。
PowerShell
wsl --install # 默认安装 Ubuntu wsl --set-default-version 2验证 GPU 状态: 确保驱动已更新,输入
nvidia-smi看到显存信息即为正常。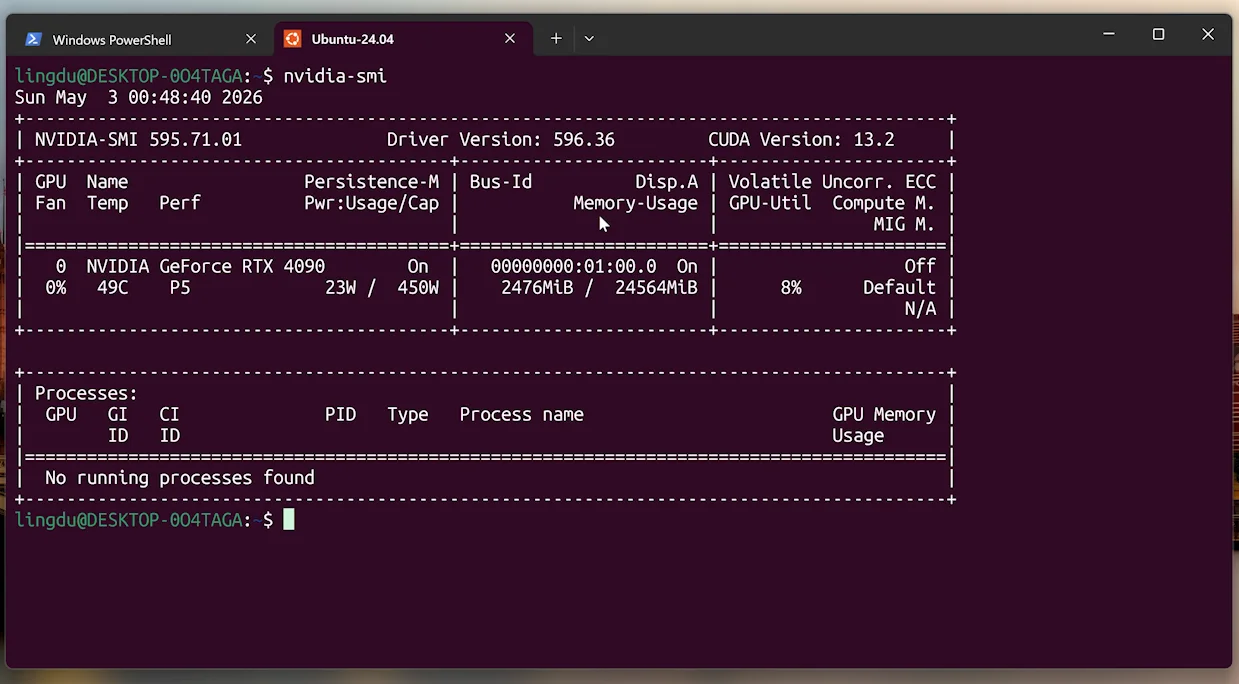
第二步:核心动力 —— 安装 llama.cpp
我们采用 llama.cpp 方案,它对显存的利用更灵活,支持 GGUF 量化格式。
安装构建工具:
Bash
sudo apt update && sudo apt install -y cmake build-essential git编译(开启 CUDA 加速):
注意: 请根据你的显卡架构修改
CMAKE_CUDA_ARCHITECTURES(例如 RTX 4090 为 89)。Bash
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=89 cmake --build build -j$(nproc)
第三步:模型下载与参数适配
根据你的显存大小(VRAM)灵活选择模型尺寸:
24G 显存(如 RTX 3090/4090): 推荐 Qwen3.6-27B-Q4_K。
12G/16G 显存: 建议选择 Qwen3.6-7B 或更小参数的版本。
启动服务命令示例:
Bash
~/llama.cpp/build/bin/llama-server \
--model ~/models/Qwen3.6-27B-UD-Q4_K_XL.gguf \
--n-gpu-layers 99 \
--ctx-size 32768 \
--flash-attn on \
--port 8080
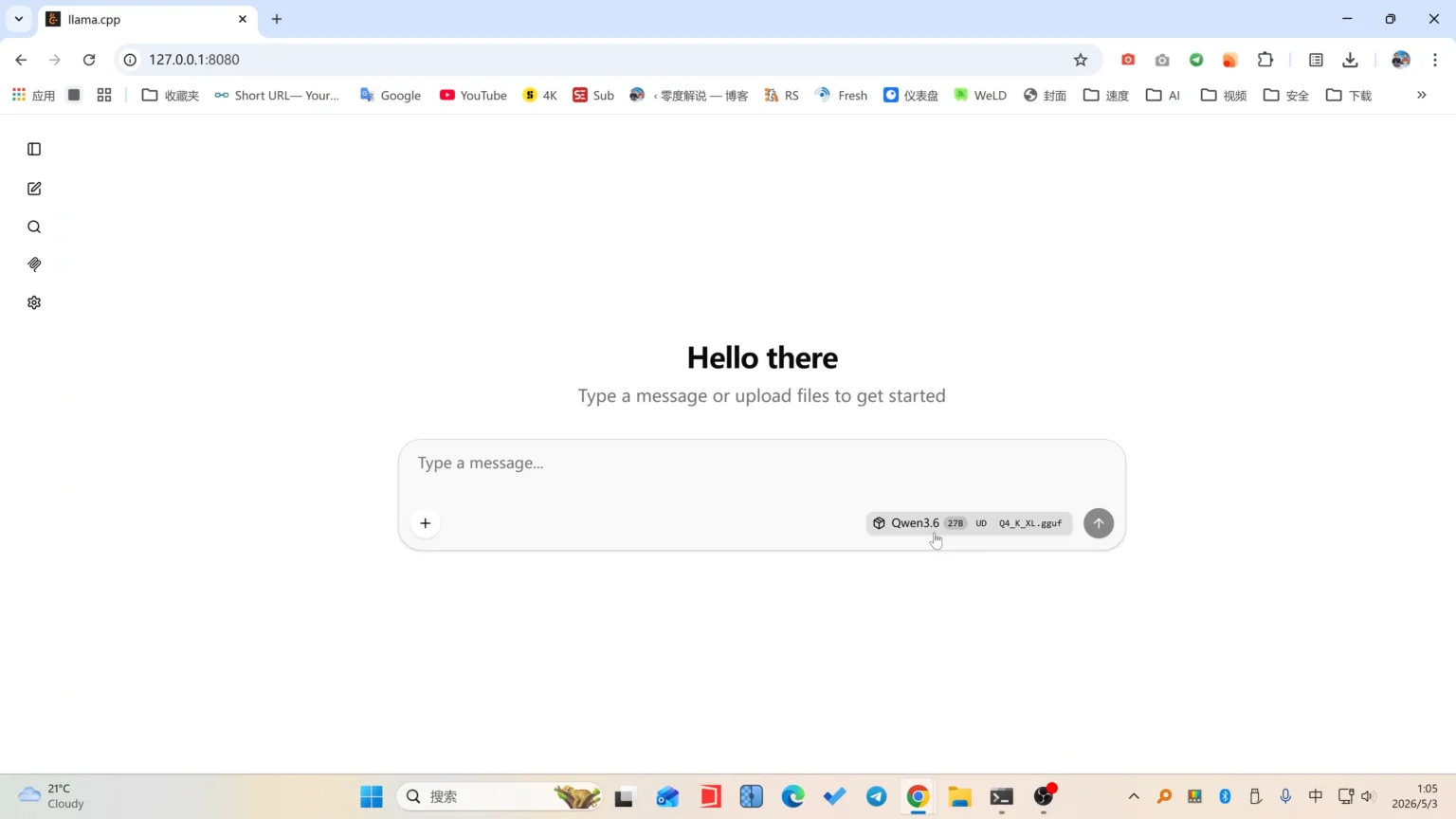
现在打开 Windows 浏览器访问:http://localhost:8080,就能看到内置聊天界面,直接开始和 Qwen3.6-27B 对话了。
第四步:注入灵魂 —— 对接 Hermes Agent
Hermes Agent 让 AI 拥有“手脚”,可以调用工具。
一键安装:
Bash
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash 安装程序会自动处理所有依赖(Python、Node.js、ripgrep、ffmpeg),你只需要有 git 就行。配置 Endpoint: 选择
Custom endpoint,填入本地地址http://localhost:8080/v1。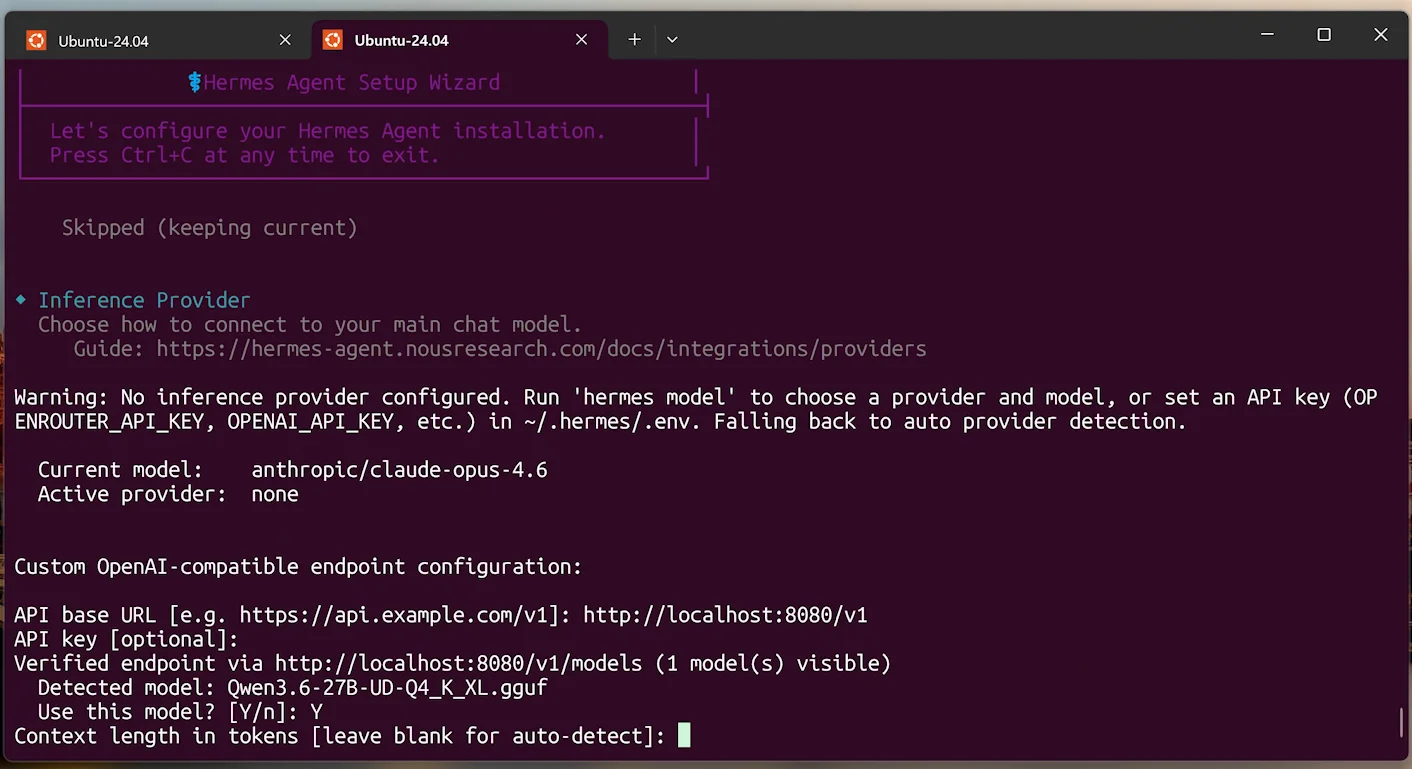
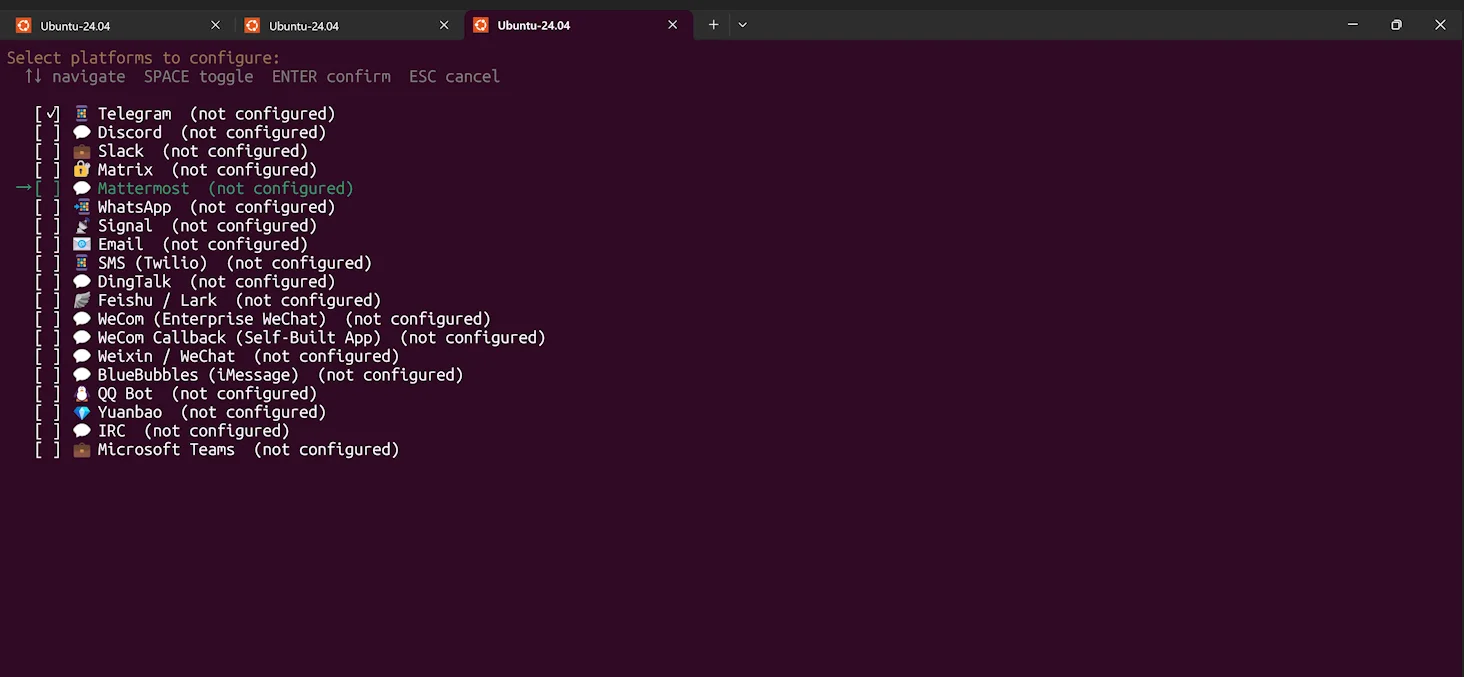
接下来就按照提示,进行配置即可,比如我们可以对接第三方聊天工具:Telegram,当然你可以选择微信、QQ、Discord等


评论区