


随着 llama.cpp 官方发布 b9196 版本,Windows 用户折腾本地 AI 大模型的门槛被彻底打碎!
以前阻碍新手构建本地 AI 的“五座大山”——CUDA 版本不匹配、DLL 缺失、驱动不兼容、CMake 编译失败、环境变量错误,如今全被官方的预编译福利解决了。现在基本可以做到:下载 → 解压 → 双击运行。llama.cpp官方下载【点击前往】【国内网盘下载】
本文将带你深度盘点这一里程碑更新,并手把手教你如何部署多模态视觉模型及热门的“无审查(Uncensored)”大模型。
一、 硬件精准匹配:你该下载哪个版本?
llama.cpp 官方 Release 页面目前针对 Windows 平台提供了极度细分的二进制包。请根据你的显卡配置对号入座:
二、 基础实战:一键启动常规 GGUF 模型
下载对应版本的压缩包并解压,在 llama.cpp 根目录下新建一个名为 models 的文件夹,将下载好的 .gguf 模型文件放进去。
打开 Windows Terminal 或 CMD,切换到解压目录,运行以下命令:
Bash
llama-server.exe -m models/gemma-4-31b-jang-crack-Q4_K_M.gguf -ngl 999
💡 核心参数解析:
-m:指定模型路径。
-ngl 999(Number of GPU Layers):代表将大模型的所有层尽量“全卸载”到显卡 VRAM 中。如果显存溢出(OOM),可以适当调低该数值(如-ngl 32)。
启动成功后,控制台会输出一个本地链接。在浏览器中打开 [http://127.0.0.1:8080](http://127.0.0.1:8080),即可直接进入 llama.cpp 内置的 Web 聊天交互界面,且该接口原生兼容 OpenAI 风格 API。
三、 进阶实战:部署 Qwen2.5-VL 多模态视觉模型
当前的 llama.cpp 已经完美支持多模态(Vision)模型。要在本地实现 OCR 识别、截图理解或网页分析,需要同时加载主模型和视觉投影模型(mmproj)。
1. 准备模型文件
从 Hugging Face 或相关镜像站下载以下两个文件并放入 models 目录:
主模型:
Qwen2.5-VL-7B-Instruct-Q4_K_M.gguf视觉模型:
mmproj-BF16.gguf
2. 启动多模态服务
Bash
llama-server.exe -m "models\Qwen2.5-VL-7B-Instruct-Q4_K_M.gguf" --mmproj "models\mmproj-BF16.gguf" -ngl 999
此时打开 Web 界面,你就可以直接上传图片,让本地 AI 帮你分析代码架构、测试视频封面点击率或提取表格数据。
四、 玩转“无审查(Uncensored / Abliterated)”模型
官方开源的大模型通常有非常严格的安全对齐层,容易对很多正常的编程技术探讨、创意写作或角色扮演(Roleplay)场景产生“道德误判”。通过社区的 Abliteration 技术,移除限制后的越狱模型在本地跑起来更加听话、高效。
热门无审查模型推荐:
Gemma-4-31b-jang-crack:基于 Google 技术演进的无审查大模型。长上下文(原生 128K)处理能力极强,写代码、啃技术手册不会轻易“失忆”。【模型下载】【国内网盘下载】
Llama3-8b-DarkIdol:目前在 Roleplay 社区非常火爆,原生支持中、英、日三语,非常适合本地部署娱乐。【模型下载】【国内网盘下载】
附:如何将 Hugging Face 模型自行量化为 GGUF?
如果你下载的是原始的 HF 格式模型,可以通过以下步骤自行转换并量化:
Bash
# 1. 克隆源码并安装依赖
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
pip install -r requirements.txt
# 2. 转换为 F16 格式的 GGUF
python convert_hf_to_gguf.py ../DarkIdol-HF --outtype f16 --outfile ../DarkIdol-F16.gguf
# 3. 压制量化为经典的 Q4_K_M 格式
llama-quantize.exe ../DarkIdol-F16.gguf ../DarkIdol-Q4_K_M.gguf Q4_K_M
五、 生产力利器:多模型自由切换自动化脚本
如果你本地下载了多个不同用途的模型(如专门聊天的 Gemma、搞视觉的 Qwen、写代码的 DeepSeek),频繁敲命令行会非常低效。
建议在 llama.cpp 的解压根目录下,新建一个文本文件,重命名为 start_model.bat。将以下经过优化的相对路径脚本复制进去(注意:保存时编码格式请选择 UTF-8,否则控制台中文会乱码):
代码段
@echo off
:: 强制启用 UTF-8 编码防止中文乱码
chcp 65001 >nul
cls
:menu
echo ==================================================
echo FuCoreAI 本地大模型一键启动工具
echo ==================================================
echo [1] 启动 Gemma 31B (无审查推理/代码/长文本)
echo [2] 启动 Qwen2.5-VL (多模态视觉/OCR/图片理解)
echo [3] 启动 DeepSeek (全能通用)
echo [4] 退出脚本
echo ==================================================
set /p choice=请输入对应数字并按回车:
if "%choice%"=="1" goto gemma
if "%choice%"=="2" goto qwen
if "%choice%"=="3" goto deepseek
if "%choice%"=="4" exit
:gemma
echo 正在启动 Gemma 31B...
llama-server.exe -m "models\gemma-4-31b-jang-crack-Q4_K_M.gguf" -ngl 999
goto end
:qwen
echo 正在启动 Qwen 视觉多模态...
llama-server.exe -m "models\Qwen2.5-VL-7B-Instruct-Q4_K_M.gguf" --mmproj "models\mmproj-BF16.gguf" -ngl 999
goto end
:deepseek
echo 正在启动 DeepSeek...
llama-server.exe -m "models\deepseek.gguf" -ngl 999
goto end
:end
pause
goto menu
双击运行这个 .bat 文件,你就可以通过简单的数字键,在不同的 AI 任务之间无缝切换了。
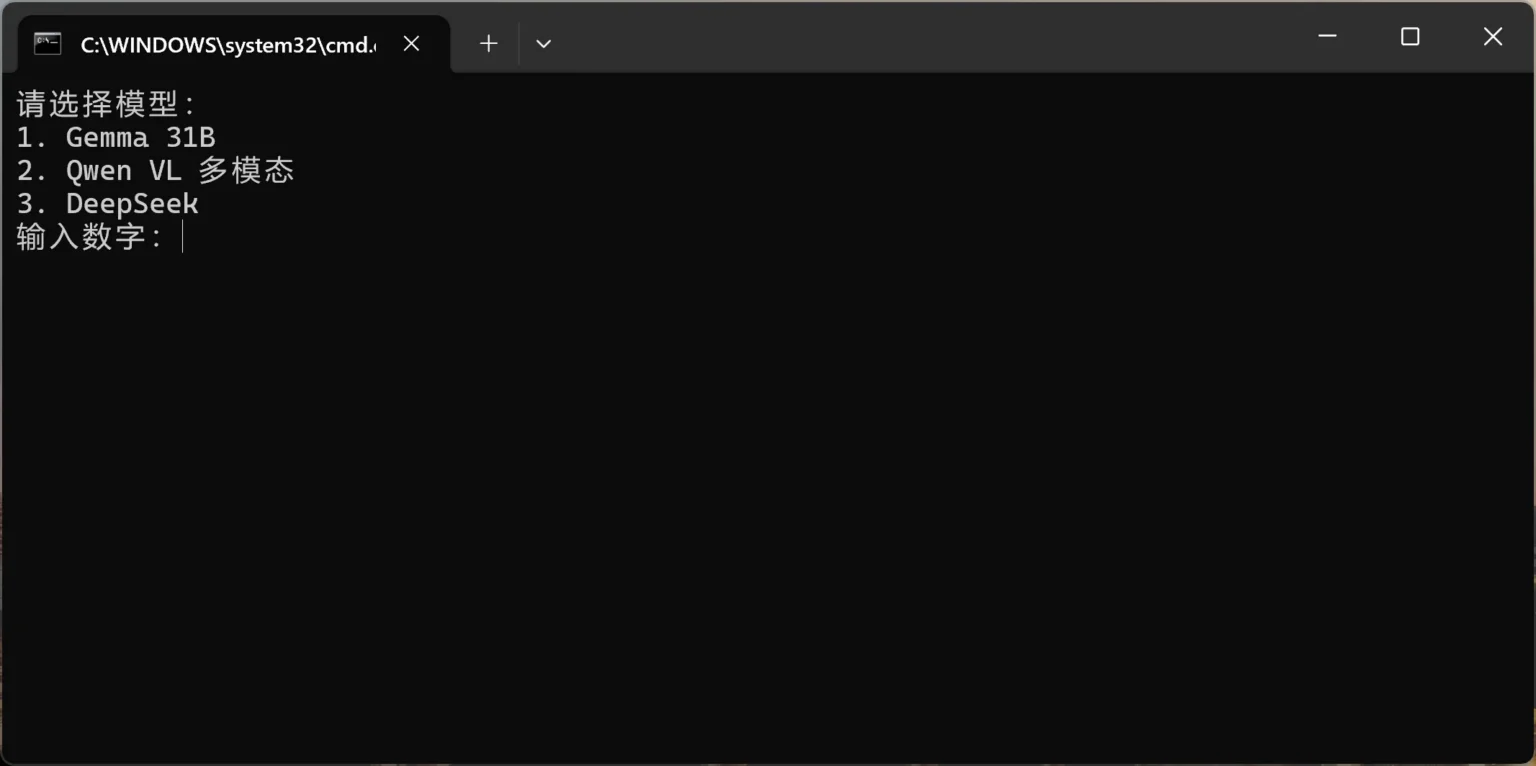
输入模型对应的数字就可以成功启动模型
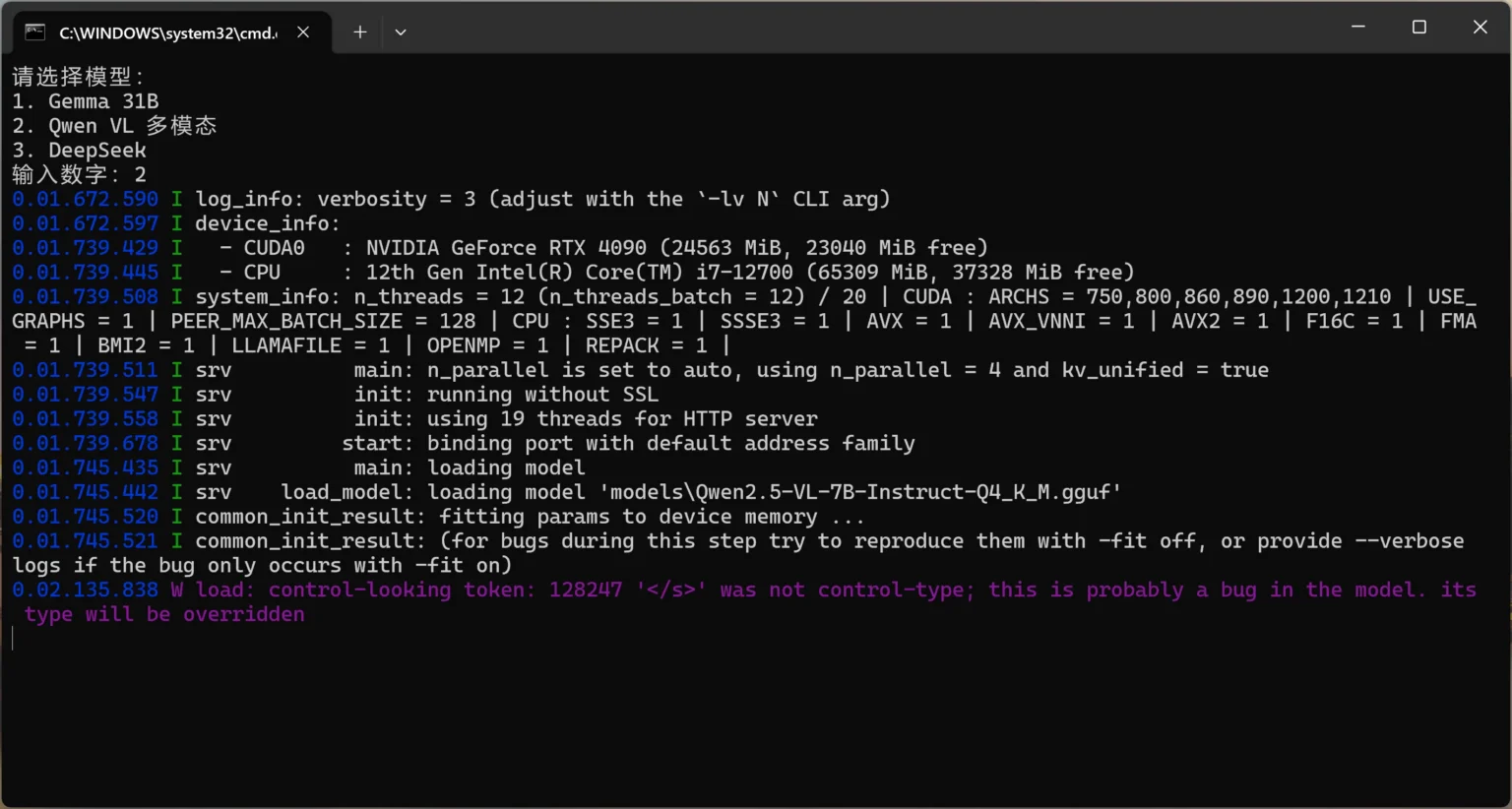
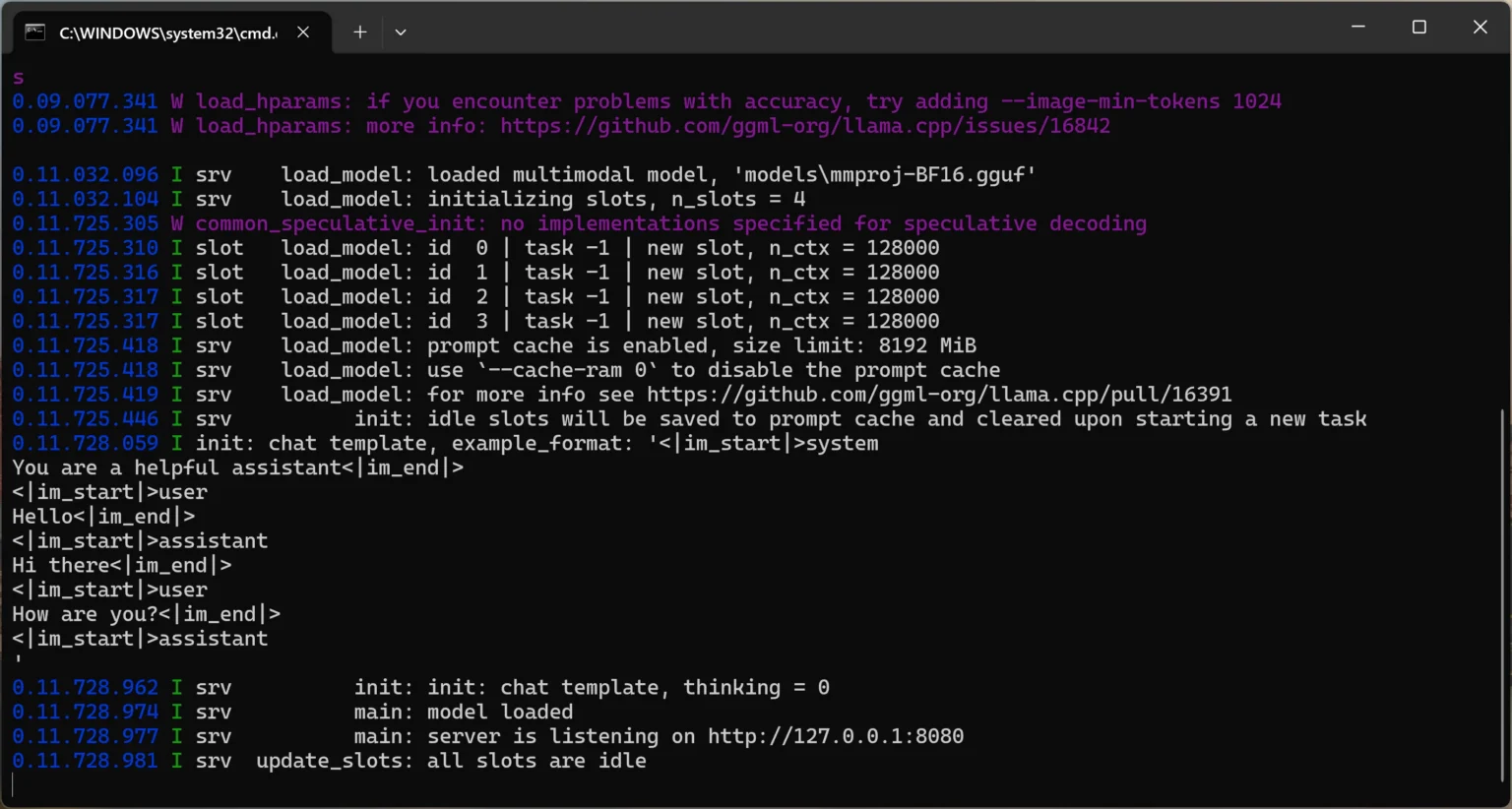
结语
llama.cpp 的这次 Windows 预编译更新,真正把本地大模型推向了“全民普适”的时代。数据不出本地,100% 隐私安全,配合免审查模型,这就是你私密的“最强第二大脑”。
更多越狱模型:1、Hermes-3 【点击下载】2、Qwen 越狱模型【点击下载】3、Deepseek 越狱模型【点击下载】


评论区