


想让 OpenClaw 自动化任务告别云端 API 的延迟与高昂成本?本文将深度解析为何 vLLM 是目前单卡本地部署的最优解,并手把手教你在 Windows WSL2 环境下通过 Qwen2.5 打造极致流畅的 AI 智能体(Agent)体验。
为什么弃用 Ollama,转向 vLLM?
在 OpenClaw 这种高频调用、长上下文的自动化场景下,常见的 Ollama 往往力不从心:
推理速度: Ollama 在并发处理和吞吐量上逊色于专门为生产环境设计的 vLLM。
工具调用(Tool Calling): OpenClaw 极其依赖模型的工具执行能力,vLLM 对
Chat Template的支持更原生。显存管理: vLLM 拥有 PagedAttention 技术,能更有效地处理长对话,避免任务中途因上下文溢出而“断片”。
一、 环境准备:搭建 WSL2 纯净底座
OpenClaw 推荐在 Linux 环境下运行以获得最佳性能。Windows 用户首选 WSL2。
安装 WSL2:
以管理员身份打开 PowerShell,执行:
PowerShell
wsl --install wsl --install -d Ubuntu重启电脑后,确保
wsl --version显示版本为 2。
GPU 直通检查:
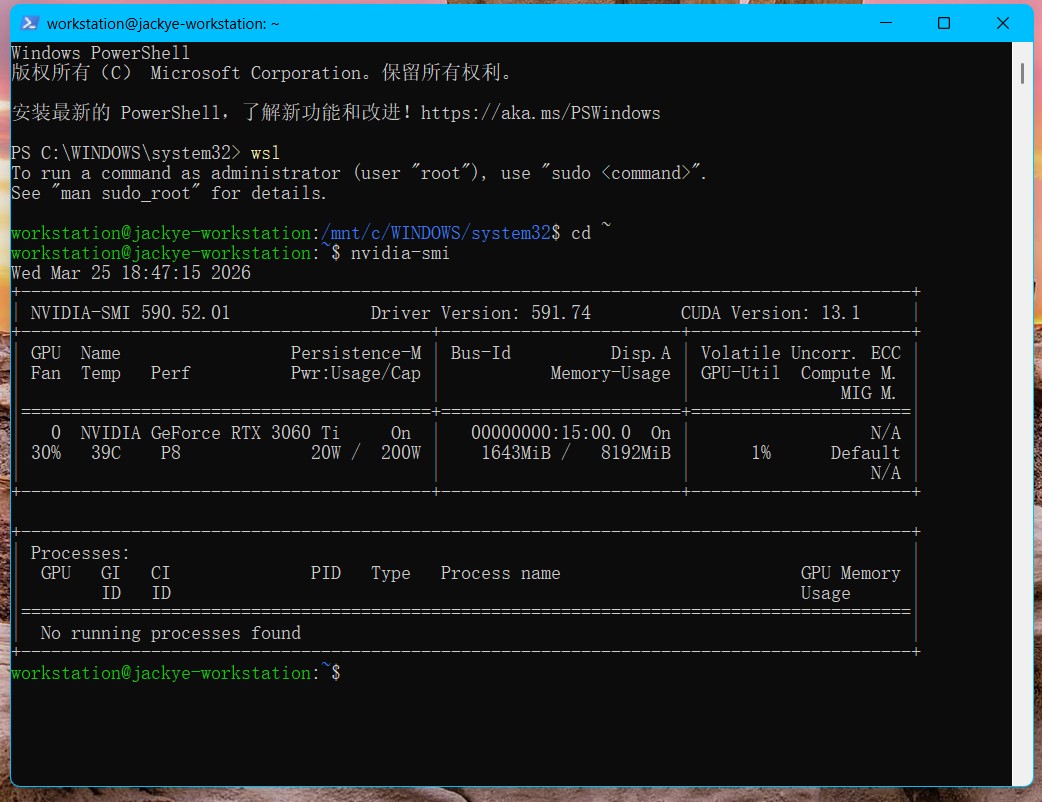
在 Ubuntu 终端输入:
Bash
nvidia-smi
若能正确显示你的 RTX 显卡信息(如 4090),说明 GPU 虚拟化成功。
二、 核心部署:vLLM 推理框架
1. 隔离环境安装
Bash
sudo apt update && sudo apt upgrade -y
sudo apt install python3-pip python3-venv -y
# 创建并激活虚拟环境
python3 -m venv vllm-env
source vllm-env/bin/activate
# 升级 pip 并安装 vLLM
pip install --upgrade pip
pip install vllm
2. 模型选型:Qwen2.5 AWQ 量化版
针对 OpenClaw 场景,强烈推荐 Qwen2.5-14B-Instruct-AWQ。
中文能力: 目前开源界最强中文对齐。
Agent 性能: 针对 Tool Calling 进行了专门强化。
显存友好: AWQ 量化在保持精度的同时,显著降低显存占用。
显存建议:
24GB (4090/3090): 首选 14B-AWQ。
12GB - 16GB (4070Ti/4080): 推荐 7B-AWQ。
8GB: 建议使用 4B 或 1.5B 规模模型。
三、 启动与优化:拉满推理性能
使用以下命令启动 API 服务,这是针对 RTX 4090 优化的最佳实践参数:
Bash
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-14B-Instruct-AWQ \
--quantization awq_marlin \
--gpu-memory-utilization 0.9 \
--max-model-len 32768 \
--enable-auto-tool-choice \
--tool-call-parser hermes
参数深度解析:
--quantization awq_marlin:利用 Marlin 内核加速 AWQ 推理。--gpu-memory-utilization 0.9:占用 90% 显存,留出 10% 缓冲防止 OOM。--tool-call-parser hermes:关键! 让模型更精准地解析 OpenClaw 的工具指令。
四、 对接 OpenClaw
1. 安装 OpenClaw
Bash
# 安装 Node.js 22
curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash -
sudo apt install -y nodejs
# 安装 OpenClaw
sudo npm install -g openclaw@latest
2. 配置自定义模型
执行 openclaw onboard,在交互式菜单中配置:
Provider:
Custom / OpenAI CompatibleBase URL:
http://127.0.0.1:8000/v1API Key:
sk-any-string(vLLM 默认不校验,随便填)Model Name:
Qwen/Qwen2.5-14B-Instruct-AWQ
五、 终极优化:长对话防卡顿策略
随着任务推进,Context 会变长导致生成变慢。可以通过以下两个维度优化:
1. OpenClaw 推荐参数
2. System Prompt 技巧
在 OpenClaw 的系统提示词中加入以下指令,引导模型自我压缩记忆:
"When the conversation history is long, please summarize previous steps into a concise 'Current Status' within 200 tokens."
六、 性能参考 (RTX 4090)
结语: 通过 vLLM 部署 Qwen2.5,你已经在本地拥有了一个不输于闭源 API 的自动化引擎。不仅数据更安全,且响应速度能让你在调试 OpenClaw 任务时效率倍增。


评论区