


为什么大模型的未来在 TPU?
在 2026 年的今天,当你运行 OpenClaw(龙虾) 或是调取 Gemini 3 的 API 时,支撑这一切的底层心脏,极大概率不是传统的显卡,而是 Google 秘密研发十年的 TPU (Tensor Processing Unit)。
从最初应对 Google 搜索压力而生的专用芯片,到如今足以撼动英伟达王座的 TPUv7 “Ironwood”,TPU 的演进史就是一部 AI 算力的革命史。今天,我们就来拆解这颗“硅片上的核武”。
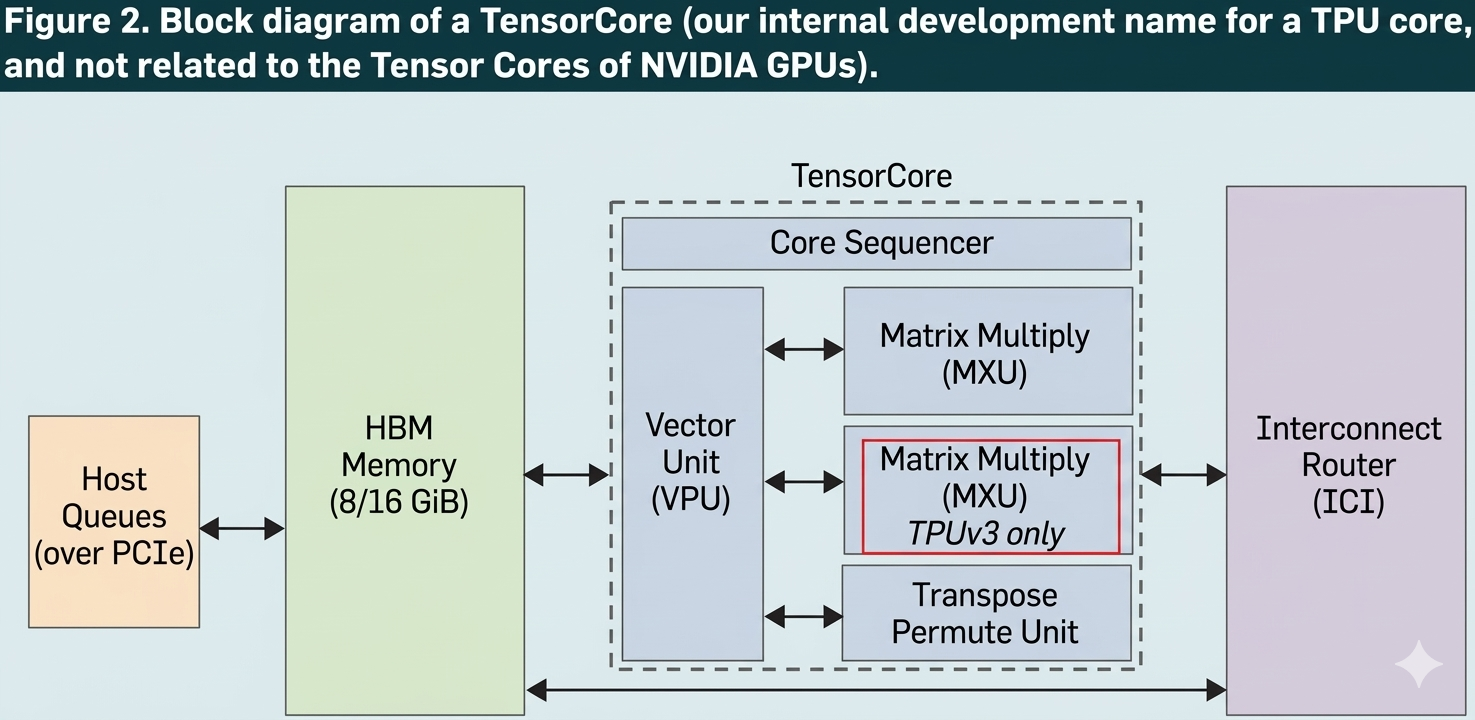
1. 核心密码:脉冲阵列 (Systolic Array)
不同于 GPU 追求极致的通用性,TPU 的核心竞争力在于它的 MXU (Matrix Multiply Unit)。
工作原理:它像流水线一样,让数据在处理单元(PE)之间直接流转,而不需要每一步都读写内存。
数据流优势:在 2026 年这个大模型横行的时代,TPU 的“输出驻留(OS)”和“权重驻留(WS)”模式极大地降低了内存带宽压力,这是它能跑赢英伟达 TCO(总拥有成本)的关键。
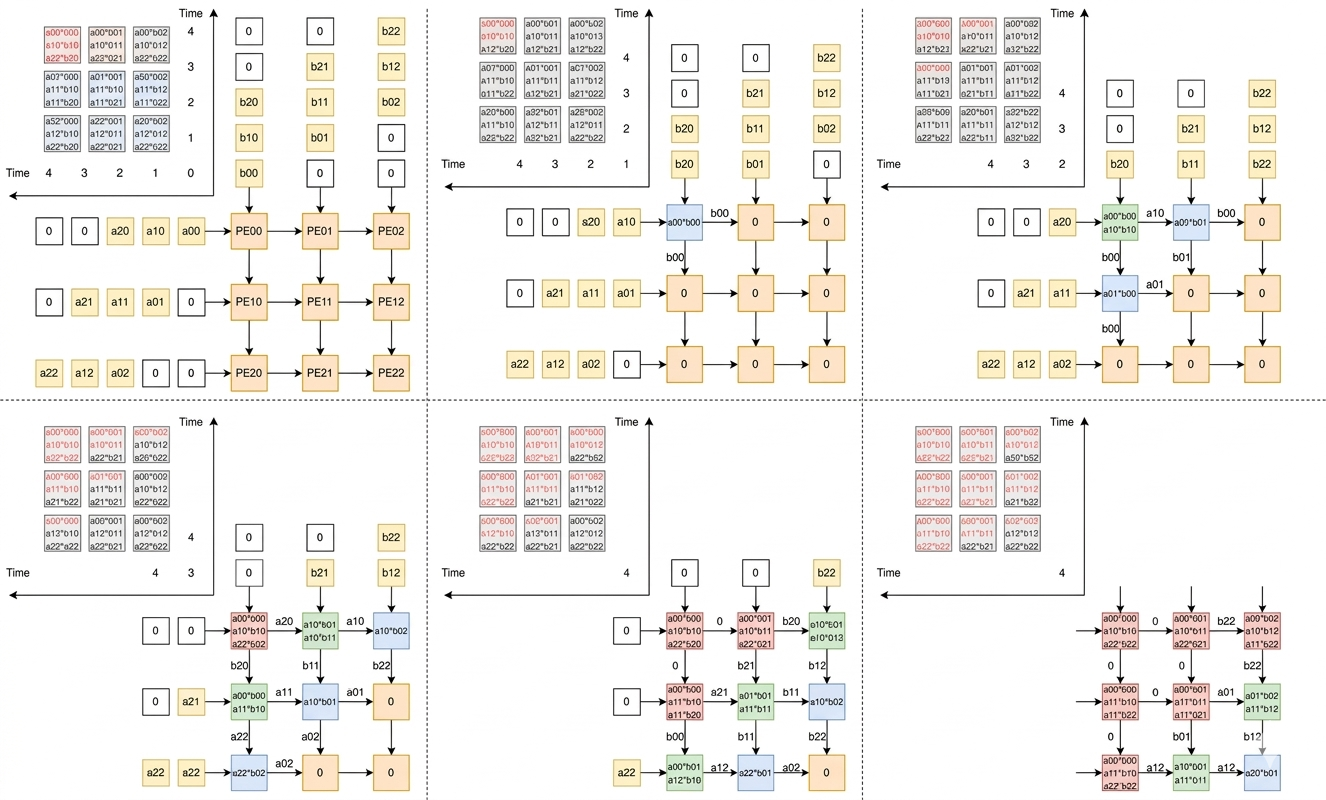
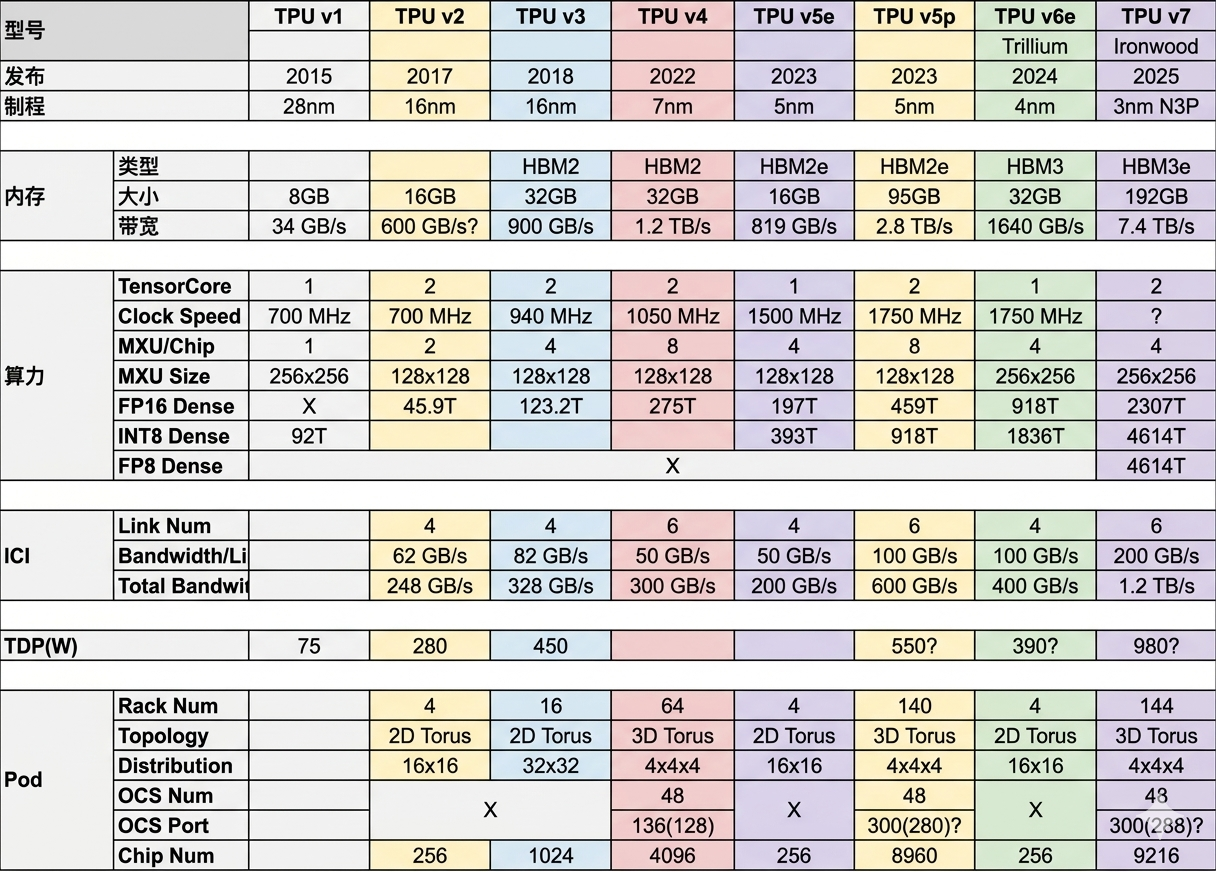
2. 从 v1 到 v7:进化的里程碑
TPUv2/v3:液冷与超级计算机的开端 从 v3 开始,Google 正式引入液冷技术,并构建了基于 2D Torus 拓扑的 Supercomputer。这是大规模预训练模型(如早期 BERT、GPT)能够跑通的技术底座。
TPUv4:光交换机 (OCS) 的降维打击 v4 是一个分水岭。Google 引入了 Palomar OCS(光学电路交换机),实现了毫秒级的网络重构。这种“弹性算力”让故障点可以被动态绕过,稳定性远超当时的传统集群。
TPUv7 Ironwood:2026 年的“暴力美学” 作为最新的“王牌”,TPUv7 首次采用了双计算 Die 设计。
算力巅峰:FP8 算力达到了惊人的 4614 TFLOPs。
内存革命:配备了 192GB 的 HBM3e,带宽高达 7.3TB/s。
SparseCores:专门针对推荐系统和 OpenClaw 等 Agent 涉及的“嵌入查找(Embedding Lookup)”进行了硬件级加速。
3. 为什么 2026 年的开发者更爱 TPU?
过去阻碍 TPU 普及的唯一门槛是“软件生态”。但在 2026 年,这个阻碍已经消失:
PyTorch Native:谷歌彻底填平了 JAX 与 PyTorch 的鸿沟,现在的开发者可以像写 CUDA 代码一样轻松调用 TPU 算力。
算力普惠:正如 36Kr 报道,TPU 的 TCO 比英伟达 GB200 低了近 44%。在“养龙虾”消耗巨额 Token 的今天,性价比就是生命线。


评论区