


强化学习和智能体使用、上下文内存存储、DRAM 定价影响、CPU 互连演进、AMD Venice、Verano、Florence、Intel Diamond Rapids、Coral Rapids、Arm Phoenix + Venom、Graviton 5、Axion

自 2023 年以来,数据中心的发展趋势很简单:GPU 和网络才是王道。人工智能训练和推理的出现及其随后的爆发式增长,使得计算需求从 CPU 转向了 GPU。这意味着服务器 CPU 的主要供应商英特尔未能搭上数据中心建设和支出的顺风车。由于超大规模数据中心和新型云平台将重心放在 GPU 和数据中心基础设施上,服务器 CPU 的收入一直相对停滞不前。
与此同时,这些超大规模数据中心运营商也纷纷为其云计算服务开发基于 ARM 架构的数据中心 CPU,这无疑蚕食了英特尔的一大潜在市场。而在英特尔自身的 x86 领域,其执行力不足、性能远逊于竞争对手 AMD,进一步蚕食了市场份额。由于缺乏有效的 AI 加速器产品,英特尔只能原地踏步,眼睁睁地看着其他厂商大举扩张。
过去六个月,情况发生了巨大变化。我们已向 Core Research 和 Tokenomics Model 提交了多份报告 ,指出 CPU 需求飙升。我们展示并建模的主要驱动因素是强化学习和 Vibe 编码对 CPU 的巨大需求。此外,我们还报道了多家拥有人工智能实验室的厂商达成的重大 CPU 云交易。我们还建立了模型,分析了各种类型 CPU 的部署数量。
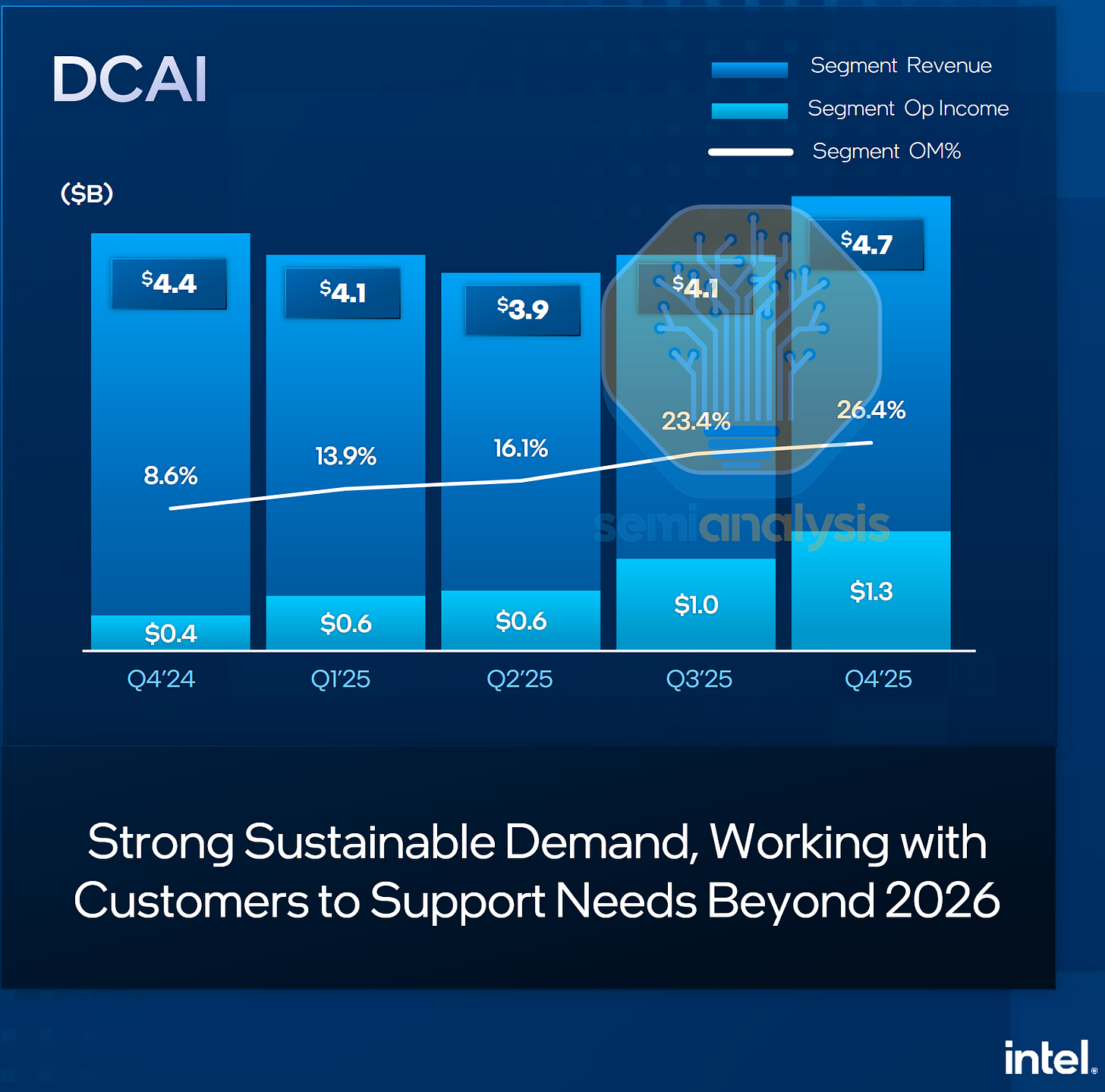
然而,英特尔近期的股价反弹以及 2025 年下半年不断变化的市场需求信号表明,CPU 如今再次变得至关重要。在最新的第四季度财报中,英特尔预计 2025 年下半年数据中心 CPU 需求将出现意外增长,并因此提高了 2026 年在晶圆代工设备方面的资本支出预期,同时将晶圆生产从 PC 转向服务器,以缓解供应紧张,满足这一新增需求。这标志着 CPU 在数据中心领域的作用迎来了一个转折点,人工智能模型训练和推理将更加密集地依赖 CPU。
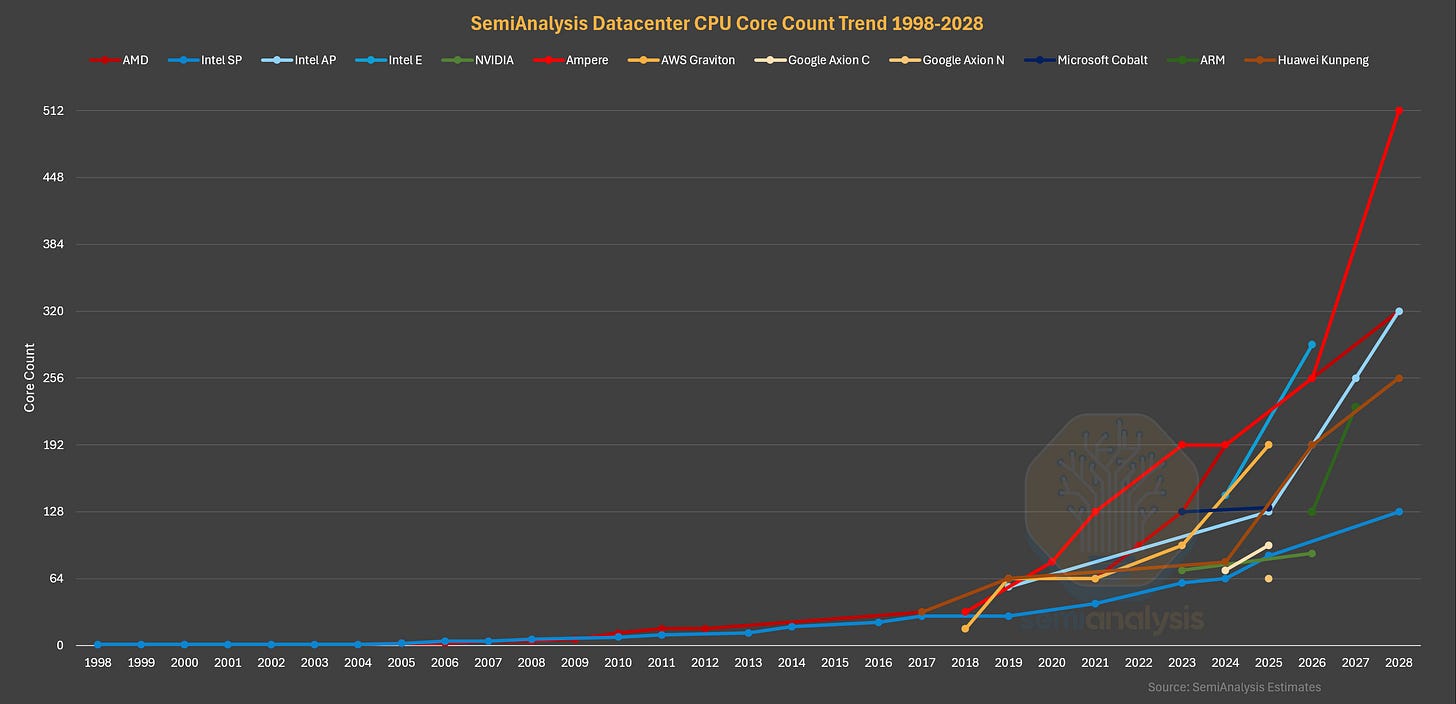
2026 年对于数据中心 CPU 而言是激动人心的一年,在市场需求激增的背景下,各厂商都将在这一年推出多款新一代产品。因此,本文旨在描绘 2026 年的 CPU 市场格局。我们将首先介绍数据中心 CPU 的发展历程和不断变化的市场需求驱动因素,并深入分析英特尔和 AMD 多年来在数据中心 CPU 架构方面的变革。
接下来,我们将重点关注 2026 年的 CPU,全面分析英特尔的 Clearwater Forest、Diamond Rapids 和 AMD 的 Venice,以及它们在设计上的有趣趋同(和分歧),讨论性能差异,并预览我们的 CPU 成本分析。
接下来,我们将详细介绍 ARM 的竞争格局,包括 NVIDIA 的 Grace 和 Vera、亚马逊的 Graviton 系列、微软的 Cobalt、谷歌的 Axion CPU 系列、Ampere Computing 的商业 ARM 芯片竞标及其被软银收购、ARM 自己的 Phoenix CPU 设计,以及华为自主研发的鲲鹏 CPU。
我们为订阅用户提供至 2028 年的数据中心 CPU 路线图,并详细介绍 AMD、Intel、ARM 和 Qualcomm 在 2026 年之后的数据中心 CPU 产品线。随后,我们将展望数据中心 CPU 的未来发展趋势,探讨 DRAM 短缺的影响,NVIDIA 的 Bluefield-4 上下文内存存储平台对通用 CPU 未来发展的意义,以及 CPU 市场和 CPU 设计领域未来值得关注的关键趋势。
数据中心 CPU 的作用和演变
个人电脑时代

现代数据中心 CPU 的雏形可以追溯到 20 世纪 90 年代,这得益于前十年个人电脑的成功,它将基础计算带入了千家万户。随着英特尔 i386、i486 和奔腾系列处理器的问世,个人电脑的处理能力不断提升,许多原本由 DEC 和 IBM 等公司的高级工作站和大型机完成的任务,如今都可以在个人电脑上以更低的成本完成。为了满足这种对高性能“大型机替代品”的需求,英特尔开始推出性能更强、缓存更大、价格也更高的个人电脑处理器。1995 年推出的奔腾 Pro 处理器便是其中的代表,它将多个二级缓存芯片与 CPU 封装在多芯片模块(MCM)中。1998 年,至强系列处理器也效仿此举,推出了奔腾 II 至强处理器,同样在 CPU 插槽中增加了多个二级缓存芯片。虽然如今 IBM Z 系列大型机仍然用于银行交易验证等用途,但它们仍然是市场的一个小众领域,我们不会在本文中进行介绍。
互联网泡沫时代
21 世纪初,随着 Web 2.0、电子邮件、电子商务、谷歌搜索、配备 3G 宽带数据的智能手机的出现,以及全球互联网流量激增,数据中心 CPU 的需求也随之增长,以应对万物互联带来的挑战。数据中心 CPU 市场迅速发展成为一个价值数十亿美元的庞大产业。在设计方面,随着 Dennard 缩放定律的终结,GHz 之争告一段落,人们的关注点转向了多核 CPU 和更高的集成度。AMD 将内存控制器集成到 CPU 芯片中,高速 I/O(PCIe)也直接来自 CPU。多核 CPU 尤其适用于数据中心工作负载,因为它可以将多个任务在不同的核心上并行运行。
我们将在下文互连部分详细介绍这些多核处理器的连接方式演变。与此同时,AMD 和 Intel 都推出了同步多线程 (SMT) 技术,该技术将一个核心划分为两个逻辑线程,这两个线程可以独立运行,同时共享大部分核心资源,从而进一步提升了可并行处理的数据中心工作负载的性能。追求更高性能的用户会转向多路 CPU 服务器,Intel 的快速路径互连 (QPI) 和 AMD 的 HyperTransport Direct Connect 架构在其 Opteron CPU 中实现了每台服务器最多八个 CPU 插槽之间的无缝连接。
虚拟化和云计算超大规模时代
下一个重大转折点出现在 2000 年代末期云计算的兴起,并成为 2010 年代数据中心 CPU 销售的主要增长动力。与如今 GPU Neocloud 的运行方式类似,随着客户将资本支出(CapEx)转向运营支出(OpEx),计算资源开始向公共云提供商和亚马逊网络服务(AWS)等超大规模云服务商集中。受大衰退的影响,许多企业无力购买和运行自己的服务器来运行其软件和服务。
云计算提供了一种更易于接受的“按需付费”商业模式,用户可以租用计算实例并在第三方硬件上运行工作负载,从而可以根据使用情况随时间动态调整支出。这种可扩展性比购置自有服务器更具优势,因为自有服务器需要始终满负荷运行才能最大化投资回报率。云计算还催生了更多精简的服务,例如 AWS Lambda 等无服务器计算服务,它可以自动将软件分配给计算资源,免去了客户在运行特定任务前决定启动多少实例的麻烦。由于几乎所有工作都在后台完成,云计算将计算变成了一种商品。

安全高效的云环境能否正常运行的关键在于 CPU 硬件虚拟化。本质上,虚拟化允许单个 CPU 运行多个独立且安全的虚拟机(VM)实例,这些实例通过 VMware ESXi 等虚拟机管理程序进行协调。多核 CPU 可以被划分,每个 VM 被分配到一个核心或逻辑线程,虚拟机管理程序能够通过网络将实例迁移到不同的核心、插槽或服务器上,从而优化 CPU 利用率,同时确保数据和指令不会与其他运行在同一 CPU 上的实例相互干扰。
云计算对虚拟化的需求,加上 CPU 设计者为了提升性能而采用的同步多线程(SMT)技术,最终在 2018 年被 Spectre 和 Meltdown 漏洞所利用。当两个实例运行在同一个物理核心的线程上时,攻击者可以利用 CPU 核心的分支预测功能(一种性能提升技术,它会在程序运行之前猜测、获取并执行指令,使 CPU 保持繁忙状态)来窥探并拼凑出另一个线程的数据。由于云安全可能受到威胁,服务提供商纷纷禁用 SMT 以阻止攻击。尽管有补丁和硬件修复,但禁用 SMT 后高达 30%的性能损失将一直困扰着英特尔,并在未来一些不合时宜的设计决策中显现出来,我们将在下文详细阐述。
人工智能 GPU 和 CPU 整合时代
新冠疫情期间,互联网流量激增,Zoom 通话、电子商务蓬勃发展,人们在线时间也大幅增加,数据中心 CPU 需求量也达到了历史新高。在 ChatGPT 于 2022 年 11 月发布前的五年里,英特尔已向云端和企业数据中心交付了超过 1 亿颗至强可扩展 CPU。
从那时起,人工智能模型训练和推理服务彻底颠覆了 CPU 在数据中心中的角色,引发了 CPU 部署和设计策略的广泛变革。计算人工智能模型需要大量的矩阵乘法运算,这种运算很容易并行化,并且可以在 GPU 上大规模执行。GPU 拥有大量的向量单元阵列,最初用于渲染游戏和可视化的 3D 图形。
尽管加速器节点仍然使用主机 CPU,但其高度结构化且相对简单的计算需求并未充分利用 CPU 运行分支繁多、对延迟敏感的代码的能力。与 GPU 上数千个向量单元相比,CPU 只有几十个向量单元,因此其性能和效率比 GPU 低 100 到 1000 倍,尤其是在 AI 专用 GPU 添加了专注于矩阵乘法的张量核心之后。尽管英特尔努力通过增加 AVX512 端口和专用 AMX 加速引擎来增强向量和矩阵支持,但 CPU 在数据中心中仍然沦为辅助角色。然而,互联网服务仍然需要,而数据中心的电力资源则优先用于 GPU 计算。因此,CPU 与时俱进,最终分为两大类。
头部节点
主节点 CPU 的作用是管理连接的 GPU 并为其提供数据。为了尽可能降低尾延迟,需要高单核性能、大缓存以及高带宽的内存和 I/O。像 NVIIDA 的 Grace 这样的专用设计采用了一致性内存访问,使 GPU 能够利用 CPU 内存作为模型上下文键值缓存的扩展,这需要极高的 CPU 到 GPU 的带宽。对于主节点,每个计算节点通常配备 1 个 CPU 和 2 或 4 个 GPU。例如:
每个超级芯片配备 1 个 Vera CPU 和 2 个 Rubin GPU
每个计算托盘配备 1 个 Venice CPU 和 4 个 MI455X GPU
每个计算托盘配备 1 个 Graviton5 CPU 和 4 个 Trainium3 CPU
每个节点配备 2 个 x86 CPU 或 8 个 TPUv7
云原生套接字整合
随着 GPU 占用越来越多的数据中心电力预算,为了尽可能高效地服务于互联网的其他部分,加速了“云原生”CPU 的开发。其目标是在最佳效率(每瓦吞吐量)下,实现每个插槽的最大吞吐量和请求处理量。为了提高总吞吐量,不再增加更多更新的 CPU,而是淘汰老旧低效的服务器,并用数量少得多的云原生 CPU 取而代之。这些新 CPU 在满足总吞吐量要求的同时,功耗却大幅降低,从而降低了运营成本,并释放出电力预算用于更多的 GPU 计算。
插槽整合比例可达到 10:1 甚至更高。在新冠疫情期间云支出激增时购买的数百万台英特尔 Cascade Lake 服务器正被淘汰,取而代之的是性能相同但功耗不到其五分之一的最新 AMD 和英特尔 CPU。
从设计角度来看,这些云原生 CPU 的目标是在保证面积和功耗效率的前提下,实现更高的核心数量,但与传统 CPU 相比,其缓存和 I/O 能力有所降低。英特尔的 Sierra Forest 处理器将 Atom 核心引入数据中心。AMD 的 Bergamo 处理器则采用了面积和功耗效率更高的 Zen4 核心布局。AWS Graviton 等基于 ARM 架构的节能型设计取得了巨大成功,而 Ampere Computing 则凭借 Altra 和 AmpereOne 系列产品瞄准了云原生计算领域。
现实生活与智能体时代
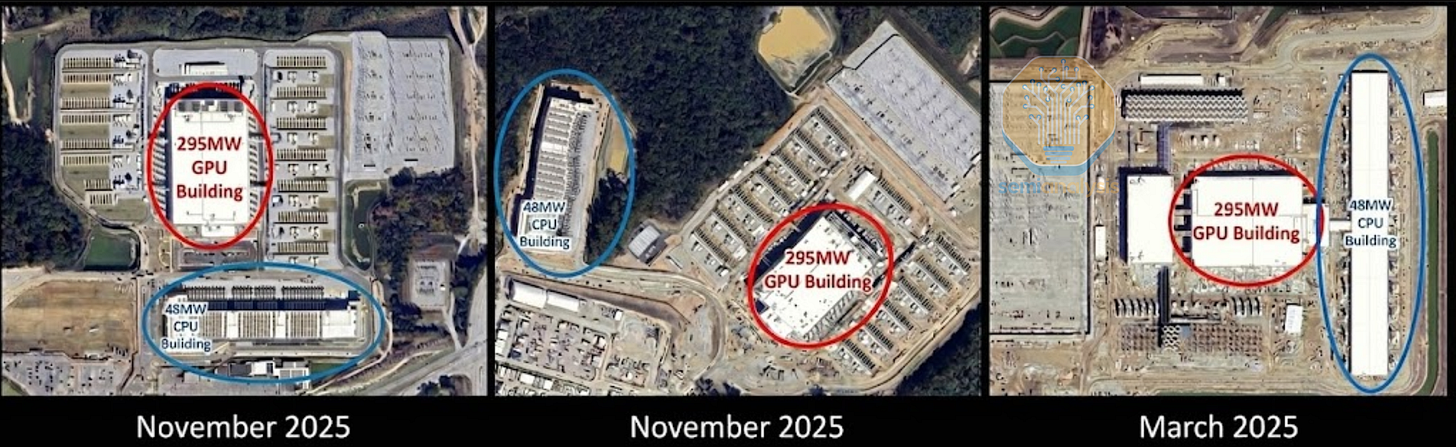
如今,为了支持主节点之外的 AI 训练和推理,CPU 使用率再次加速增长。我们已经可以在微软为 OpenAI 打造的“Fairwater”数据中心看到这种趋势。该数据中心配备了一座 48MW 的 CPU 和存储大楼,为 295MW 的主 GPU 集群提供支持。这意味着现在需要数万个 CPU 来处理和管理 GPU 生成的 PB 级数据,而如果没有 AI,这种应用场景是根本不需要的。
人工智能计算范式的演进导致了 CPU 使用率的显著提升。在预训练和模型微调阶段,CPU 用于存储、分片和索引数据,以便将其提供给 GPU 集群进行矩阵乘法运算。此外,CPU 还用于多模态模型中的图像和视频解码,尽管更多固定功能的媒体加速功能已直接集成到 GPU 中。
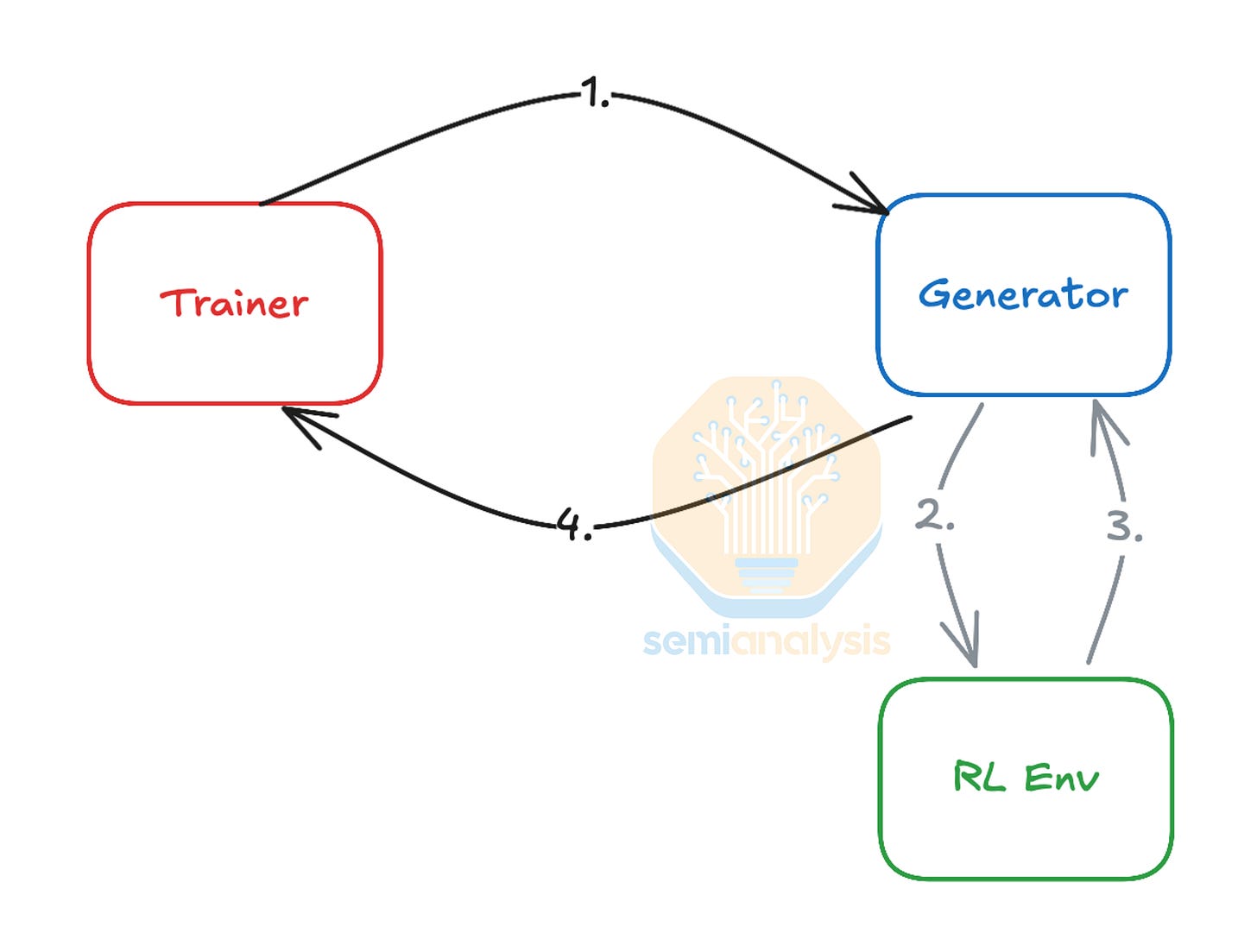
使用强化学习技术改进模型会进一步增加对 CPU 的需求。通过对强化学习的深入研究,我们发现,在强化学习训练循环中,“强化学习环境”需要执行模型生成的动作并计算相应的奖励。在编码和数学等领域,为了实现这一点,需要大量的 CPU 并行运行,以执行代码编译、验证、解释和工具使用等操作。CPU 还大量参与复杂的物理模拟以及高精度地验证生成的合成数据。为了进一步扩展模型,强化学习环境的复杂性日益增加,这就需要将大型高性能 CPU 集群部署在靠近主 GPU 集群的位置,以确保 GPU 集群保持繁忙运行并最大限度地减少 GPU 空闲时间。这种对强化学习和 CPU 在训练循环中日益增长的依赖性正在造成新的瓶颈,因为 AI 加速器的每瓦性能提升速度远超 CPU,这意味着未来的 GPU 架构(例如 Rubin)可能需要比上述 Fairwater 1:6 更高的 CPU 与 GPU 功率比。
在推理方面,检索增强生成(RAG)模型(用于搜索和使用互联网)以及智能体模型(用于调用工具和查询数据库)的兴起,显著增加了对通用 CPU 计算能力的需求,以满足这些请求。由于能够向多个数据源发送 API 调用,每个智能体对互联网的使用强度远超人类进行简单的谷歌搜索。为了应对互联网流量的激增,AWS 和 Azure 正在大规模扩建其 Graviton 和 Cobalt 系列 CPU,并采购更多 x86 通用服务器。
展望 2026 年,数据中心对 CPU 和 DRAM 的需求只会越来越高。前沿人工智能实验室的强化学习训练所需的 CPU 资源即将耗尽,他们正与云服务提供商争夺通用 x86 CPU 服务器,以求获得 CPU 配额。英特尔面临着 CPU 库存意外减少的困境,正计划提高其至强系列处理器的价格,同时加大力度开发新的工具以提升 CPU 产能。AMD 一直在提升其供应能力,以期在服务器 CPU 市场中占据更大的份额,该公司预计 2026 年该市场将实现“强劲的两位数”增长。下文将为我们的订阅用户探讨 2026 年以后 CPU 市场格局的演变。
多核 CPU 互连技术发展史
要理解 2026 年 CPU 的设计变革和理念,我们必须了解多核 CPU 的工作原理以及随着核心数量增加互连技术的演变。多核处理器需要将这些核心连接起来。早期的双核设计,例如 2005 年英特尔的奔腾 D 和至强 Paxville,实际上只是两个独立的单核处理器,核心间的通信通过前端总线(FSB)在封装外与北桥芯片进行,北桥芯片也集成了内存控制器。同样在 2005 年推出的 AMD Athlon 64 X2 可以被视为真正的双核处理器,它在同一芯片上集成了两个核心和一个内存控制器(IMC),使得核心可以通过片上网络(NoC)数据架构直接在芯片内部相互通信,并与内存和 I/O 控制器通信。
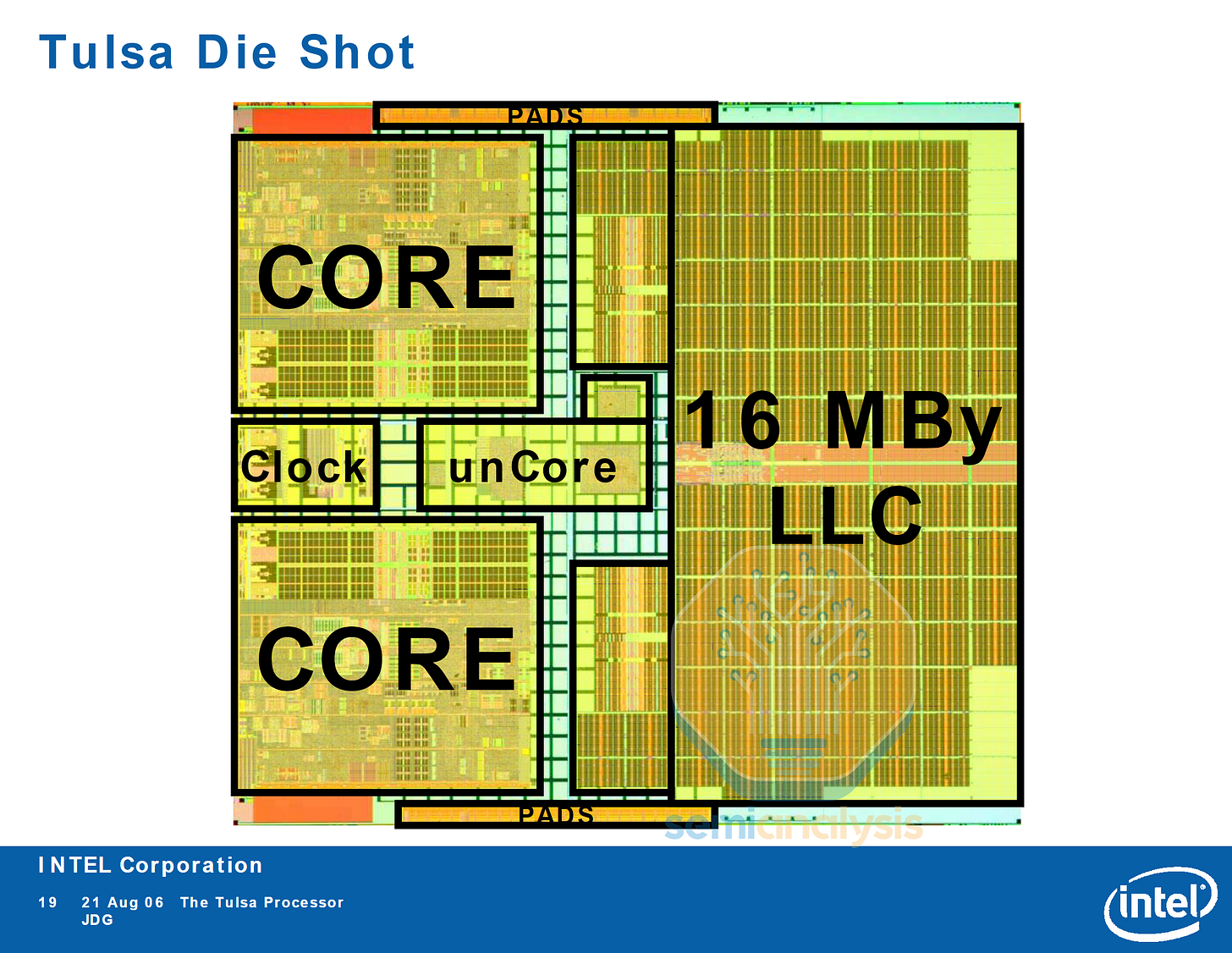
英特尔后续推出的 Tulsa 架构处理器包含 16MB 的 L3 缓存,由两个核心共享,并作为片上核心间数据交换架构。正如我们稍后将看到的,随着核心数量达到数百个,这些片上数据交换架构将成为数据中心 CPU 设计中的关键因素。
横杆限制
随着设计人员试图进一步增加核心数量,他们遇到了早期互连技术的扩展性限制。由于需要尽可能降低延迟并保持一致性,因此采用了全连接(all-to-all)的交叉开关设计,即每个核心都通过独立的链路连接到芯片上的所有其他核心。然而,随着核心数量的增加,链路数量也大幅增加,从而提高了复杂性。
2 个核心:1 个连接
4 个核心:6 个连接
6 个核心:15 个连接
8 个核心:28 个连接
大多数设计的实际极限是 4 个核心,更高核心数的处理器是通过多芯片模块和双核模块实现的,这些模块在核心对之间共享 L2 缓存和数据交换插槽。交叉开关布线通常位于共享 L3 缓存上方的金属线路中,从而节省空间。英特尔在 2008 年推出的 6 核 Dunnington 处理器使用了三个双核模块,共享 16MB L3 缓存。

AMD 于 2009 年推出了 6 核 Istanbul 处理器,采用 6 路交叉开关和 6MB L3 缓存。2010 年推出的 12 核 Magny-Cours 处理器使用了两个 6 核芯片,而 16 核 Interlagos 处理器则由两个芯片组成,每个芯片包含四个 Bulldozer 双核模块。
英特尔环形总线
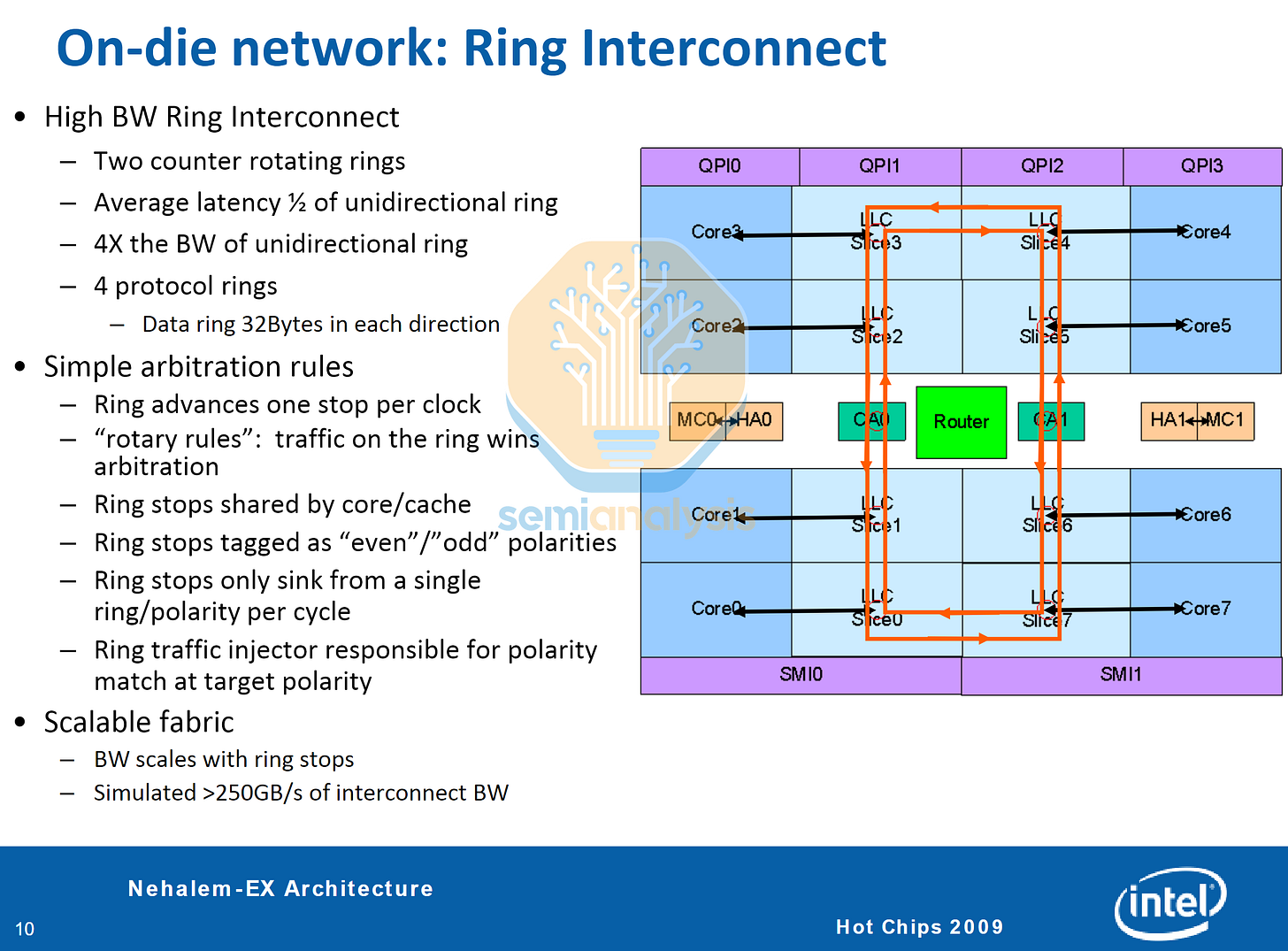
为了突破这一限制,英特尔在 2010 年推出的 Nehalem-EX(贝克顿)至强处理器中采用了环形总线架构,将 8 个核心、集成内存控制器和插槽间 QPI 链路集成到单个芯片上。环形总线架构此前已应用于 ATI Radeon GPU 和 IBM Cell 处理器,它将所有节点排列成一个环路,并将环形停止点集成到 L3 缓存切片中,同时在缓存上方的金属层中布线。缓存代理和 Home 代理负责处理核心间的内存访问以及与内存控制器的一致性。
来自每个环路节点核心和 L3 缓存切片的数据都会被排队并注入环路,数据每时钟周期前进一个节点到达目标位置。这意味着核心间的访问延迟不再均匀,位于环路两侧的核心需要比相邻核心等待更多的时钟周期。为了缓解延迟和拥塞问题,我们采用了两个反向旋转的环路,并根据地址和环路负载情况选择最佳的行进方向。由于布线复杂度得到了控制,英特尔可以将 Nehalem-EX 的核心数扩展到 8 个,Westmere-EX 的核心数扩展到 10 个。然而,如果使用单个环路继续扩展核心数,随着环路长度的增加,将会导致一致性和延迟方面的问题。
Ivy Bridge-EX 虚拟环
为了将 Ivy Bridge 架构的核心数量扩展到 15 个,英特尔在布线拓扑结构上采用了巧妙的设计。这些核心排列成三列,每列五个,并由三个“虚拟环”环绕。环限位开关控制着半环上的走线方向,从而形成一个“虚拟”的三环结构。
Haswell 和 Broadwell 双环
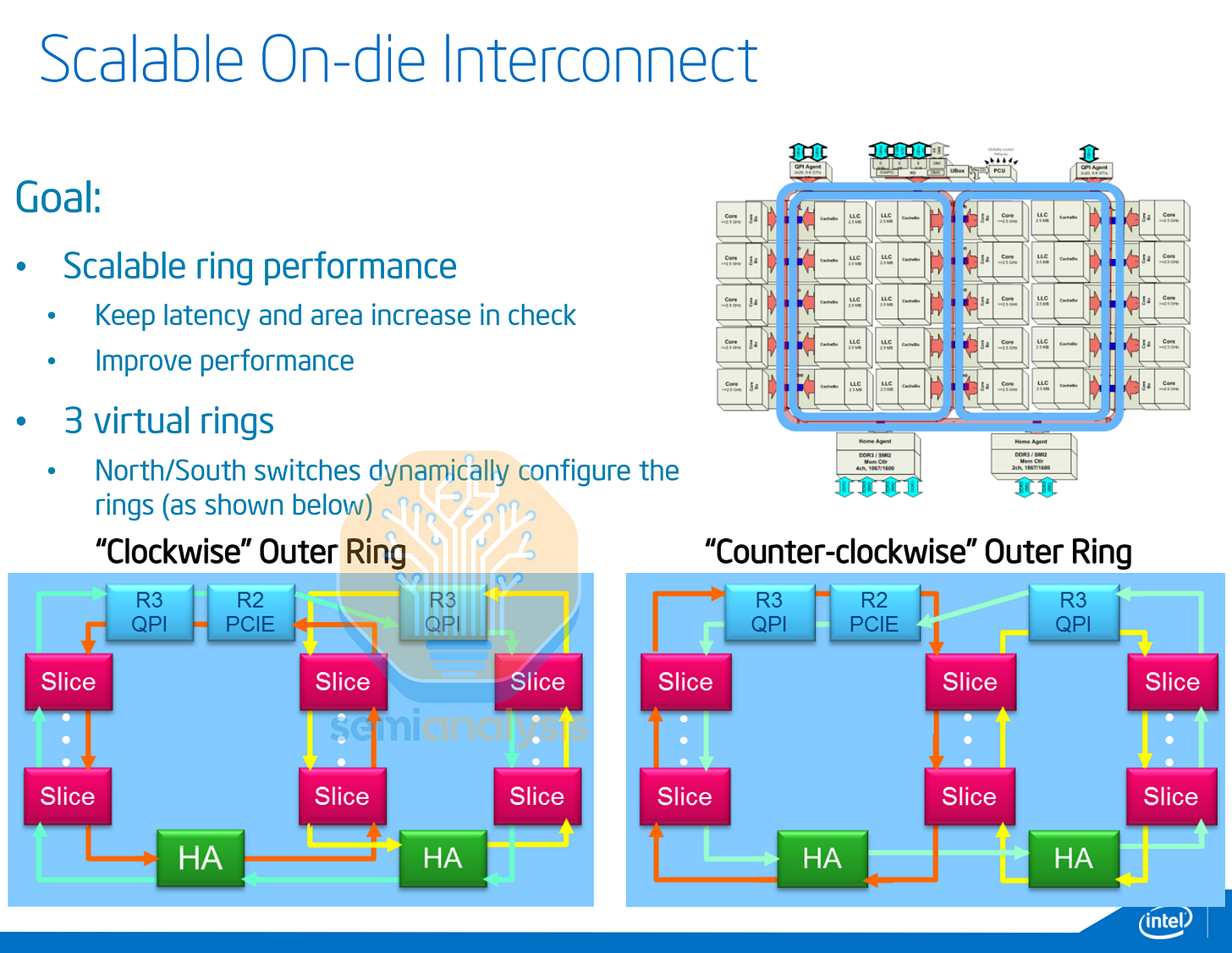
2014 年,英特尔再次改变架构,推出了 18 核 Haswell HCC 芯片,其采用双独立反向旋转环形总线,并通过一对双向缓冲交换机连接。内存控制器分布在两个环形总线上,其中 8 核环形总线还容纳了 I/O 环路挡块。MCC 芯片则将单个半环总线自身折叠起来。2015 年发布的 Broadwell HCC 芯片将核心数量提升至 24 个,采用双 12 核环形总线。
将多个环路拼接在一起的缺点是增加了核心间延迟和内存访问延迟的波动性,尤其是在一个环路中的核心访问另一个环路的内存时。这种非均匀内存访问(NUMA)对延迟敏感且核心间交互性高的程序而言,会严重影响系统性能。
为了解决这个问题,英特尔在 BIOS 中提供了一个“片上集群”(Cluster on Die)配置选项,该选项将两个环视为独立的处理器。操作系统会将 CPU 显示为两个 NUMA 节点,每个节点可以直接访问一半的本地内存和 L3 缓存。 在 CoD 模式下的测试表明,每个环内的延迟都保持在 50 纳秒以下,而访问另一个环的延迟则超过 100 纳秒,这说明了通过缓冲交换机带来的延迟损失。
虽然这些方法帮助英特尔将核心数量增加到 24 个,但这并非一个优雅且可扩展的解决方案。增加第三个环路和两组缓冲交换机过于复杂且不切实际,还会产生大量的 NUMA 集群。要支持更多核心,需要一种新的互连架构。
英特尔网状架构
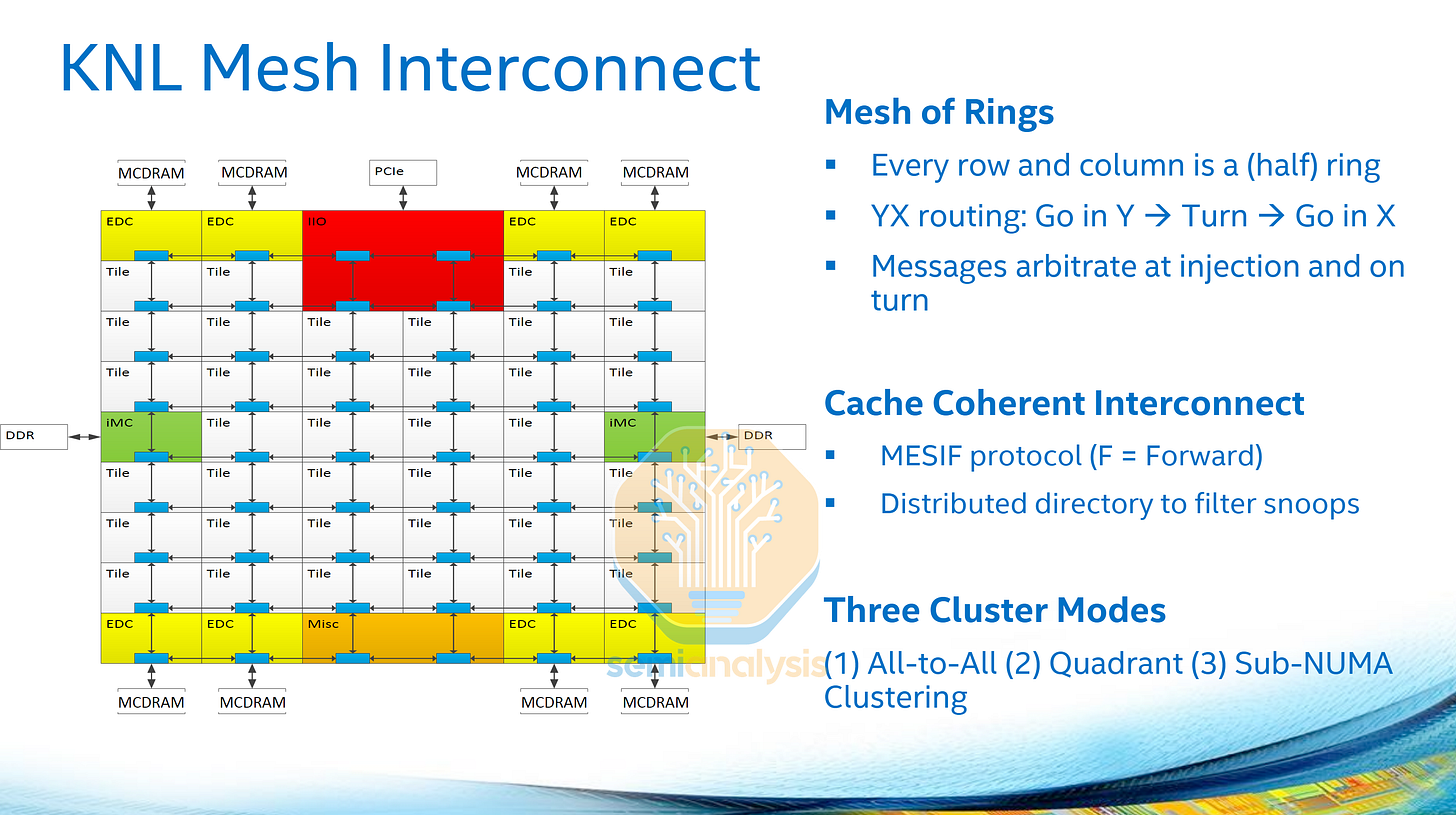
为了解决可扩展性问题,英特尔在 2017 年将其在主力 Skylake-X Xeon 可扩展处理器中采用的网状互连架构应用于 2016 年发布的 Xeon Phi“Knights Landing”处理器,并在 XCC 芯片中实现了 28 个核心。虽然核心数量相比 Broadwell 处理器并没有显著增加,但这种设计将成为未来十年核心数量扩展的基础。
在网状架构中,核心以网格形式排列,每列和每行都通过半环连接,形成二维网状阵列。每个网状节点可以容纳核心和 L3 缓存切片、PCIe I/O、IMC 和加速器。核心之间的路由以环形方式进行,数据先沿垂直方向传输,然后再水平传输。缓存代理和目标代理以及用于保证网络内存一致性的监听过滤器现在分布在所有网状节点上。
由于采用了网状网络,且多个内存控制器位于芯片的两侧,因此在大网状网络环境下,内存访问延迟和核心间延迟会存在显著差异。与早期的片上集群(Cluster on Die)方案类似,该方案提供了多种集群模式,将网状网络划分为象限以实现子 NUMA 集群(SNC),从而降低平均延迟。但代价是,每个处理器都被视为多个插槽,每个 NUMA 节点的 L3 缓存和内存访问池都较小。
在骑士登陆服务器中,每个网状节点包含两个核心,共享一个二级缓存。网状网格的大小为 6 列 9 行,顶部和底部行包含更多的 I/O 和 MCDRAM。网状网络运行在独立的时钟频率上,并且可以动态调整网状节点的时钟频率以节省功耗。在骑士登陆服务器上,网状网络的运行频率为 1.6GHz。
Skylake-X 的 28 个核心采用 6x6 网状排列,北侧设有 I/O 盖,两侧各有两个用于 IMC 的位置。由于核心尺寸的缩小,网状阵列的面积也相应缩小,从而增加了 L2 缓存,并为核心扩展了 AVX-512 指令集,以提升浮点运算性能。如果再增加一行或一列,芯片尺寸将超过 26 x 33 毫米的光栅尺寸限制。在网状阵列面积缩小且 CPU 频率高达 4.5GHz 的情况下,网状阵列的时钟频率被提升至 2.4GHz,从而实现了与 Broadwell 双环架构相近的平均延迟。
随后的 Cascade Lake 和 Cooper Lake 处理器在保持 28 核心布局的基础上进行了细微改动。作为一项独立功能,英特尔在 Cascade Lake-AP 中推出了一款 56 核心双芯片 MCM 架构,但由于 AMD 携 EPYC 重返数据中心市场,英特尔取消了 Cooper Lake CPX-4 的类似版本。
下一代 Ice Lake 处理器受益于制程工艺从 14nm 缩小到 10nm,核心数量得以提升至 40 个,采用 8x7 网格布局,这是光刻工艺限制下的最大值。然而,下一代 Sapphire Rapids 处理器仍然采用相同的制程工艺,并且拥有更多功能。这让英特尔陷入了如何再次提升核心数量的困境。
EMIB 上的分散网格

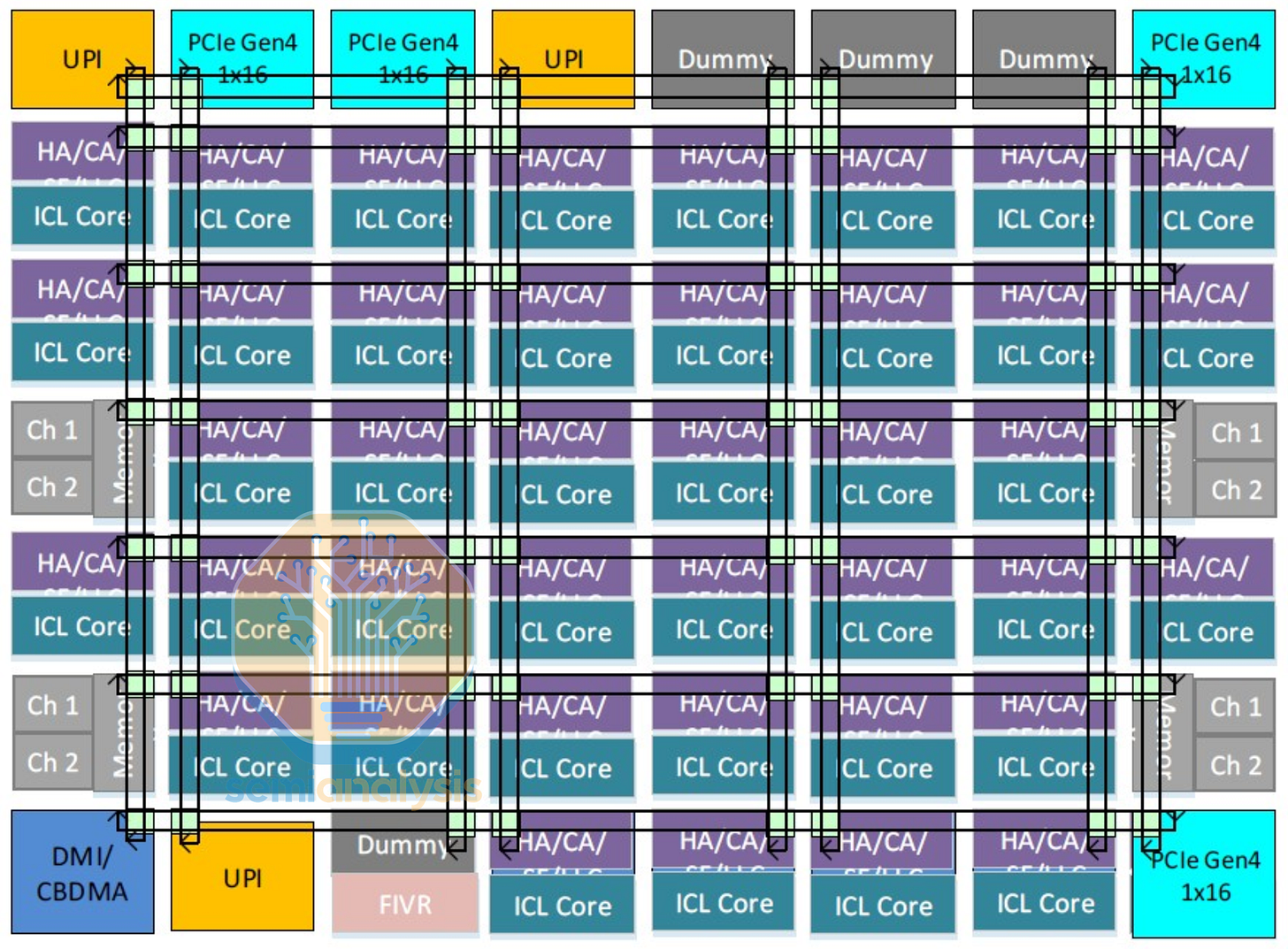
Sapphire Rapids 架构增加了用于矩阵乘法和人工智能的高级矩阵扩展 (AMX) 引擎,进一步增大了核心面积。这意味着单个芯片只能容纳 34 个核心,相比 Ice Lake 架构有所退步。为了将核心数量增加到 60 个,英特尔别无选择,只能再次将核心分散到多个芯片上。然而,他们希望保持芯片的“逻辑单片”特性,使处理器在外观和性能上与单个芯片完全相同。
因此,Sapphire Rapids 首次采用了英特尔的 EMIB 先进封装技术,实现了跨芯片的网状架构。两对镜像的 15 核芯片通过模块化芯片结构 (Modular Die Fabric) 拼接在一起,形成了一个覆盖四个象限、面积近 1600 平方毫米的 8x12 网状结构。为了应对 PCIe 5.0 翻倍吞吐量和新型数据加速器模块之间日益增长的数据传输量,I/O 接口需要采用双排网状挡板。
由于网状网络覆盖范围更大,跨越多个芯片,平均核心间延迟从 Skylake 的 47ns 增加到 59ns。为了尽可能避免使用网状网络,英特尔将每个核心的私有 L2 缓存增加到 2MB,使得芯片上的 L2 缓存容量大于 L3 缓存容量(120MB 对 112.5MB)。此外,英特尔还建议更多地使用子 NUMA 集群 (SNC) 技术,将每个芯片视为独立的象限。
尽管 Sapphire Rapids 是英特尔首次采用芯片组技术,但它却因长达数年的延期和多次修改而臭名昭著。或许是由于 EMIB 架构下网状网络的性能问题,又或许是其他执行方面的问题,最终版本直到 2023 年初才发布,而最初的路线图计划是在 2021 年发布。
随后在 2023 年底推出的 Emerald Rapids 更新版本保留了相同的核心架构和制程,但将芯片数量减少到 2 片。由于用于 EMIB 芯片间链路的硅面积减少,英特尔得以将核心数量从 60 个增加到 66 个(为提高良率,最高可达 64 个),同时还将 L3 缓存容量几乎翻了三倍,达到 320MB。
Xeon 6 上的
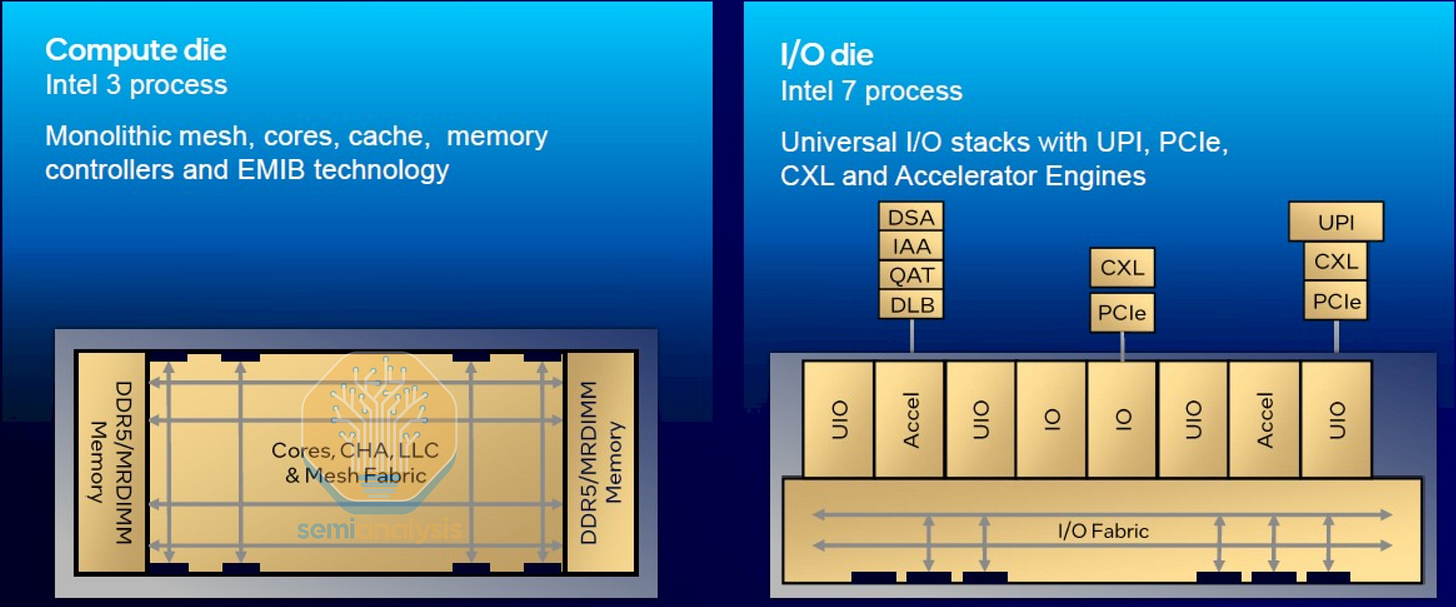
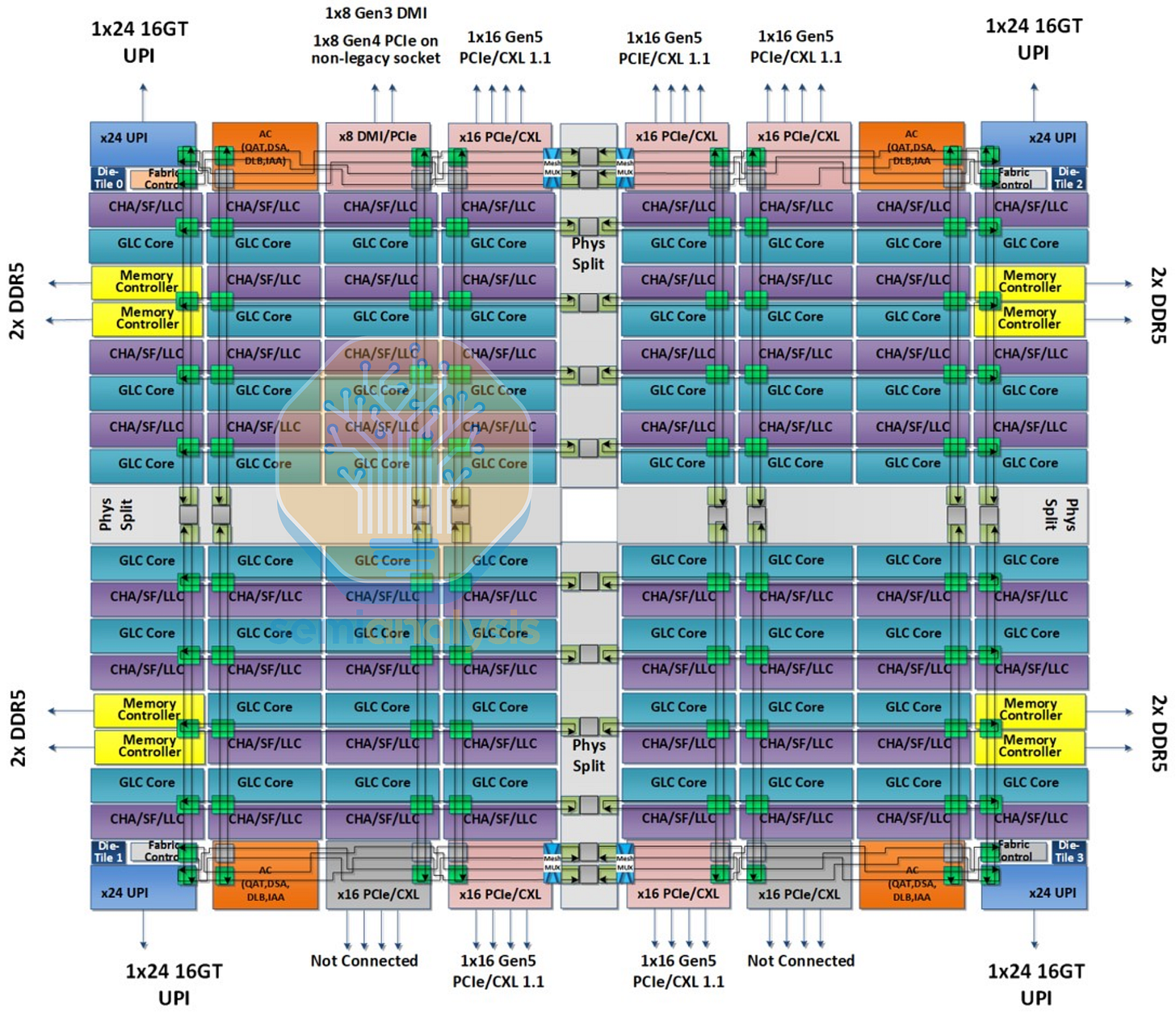
除了突破光刻限制之外,多芯片芯片设计的另一优势在于能够混合搭配不同的芯片,并在不同的变体和配置之间共享设计。对于 2024 年的下一代 Xeon 6 平台,英特尔采用了异构解耦设计,将 I/O 与核心和内存分离。这样做使得 I/O 芯片可以继续使用较旧的英特尔 7 节点,而计算芯片则迁移到英特尔 3 节点。因此,英特尔可以重用从 Sapphire Rapids 平台开发的 I/O IP,同时节省成本,因为 I/O 芯片从更先进的节点升级中获益不大。与此同时,计算芯片可以与 P 核 Granite Rapids 和 E 核 Sierra Forest 配置混合搭配,在顶级 Granite Rapids-AP Xeon 6900P 系列上最多可配备 3 个计算芯片,从而在 5 个芯片上形成一个 10x19 的大型网格,连接 132 个核心,为了提高良率,最多可启用 128 个核心。
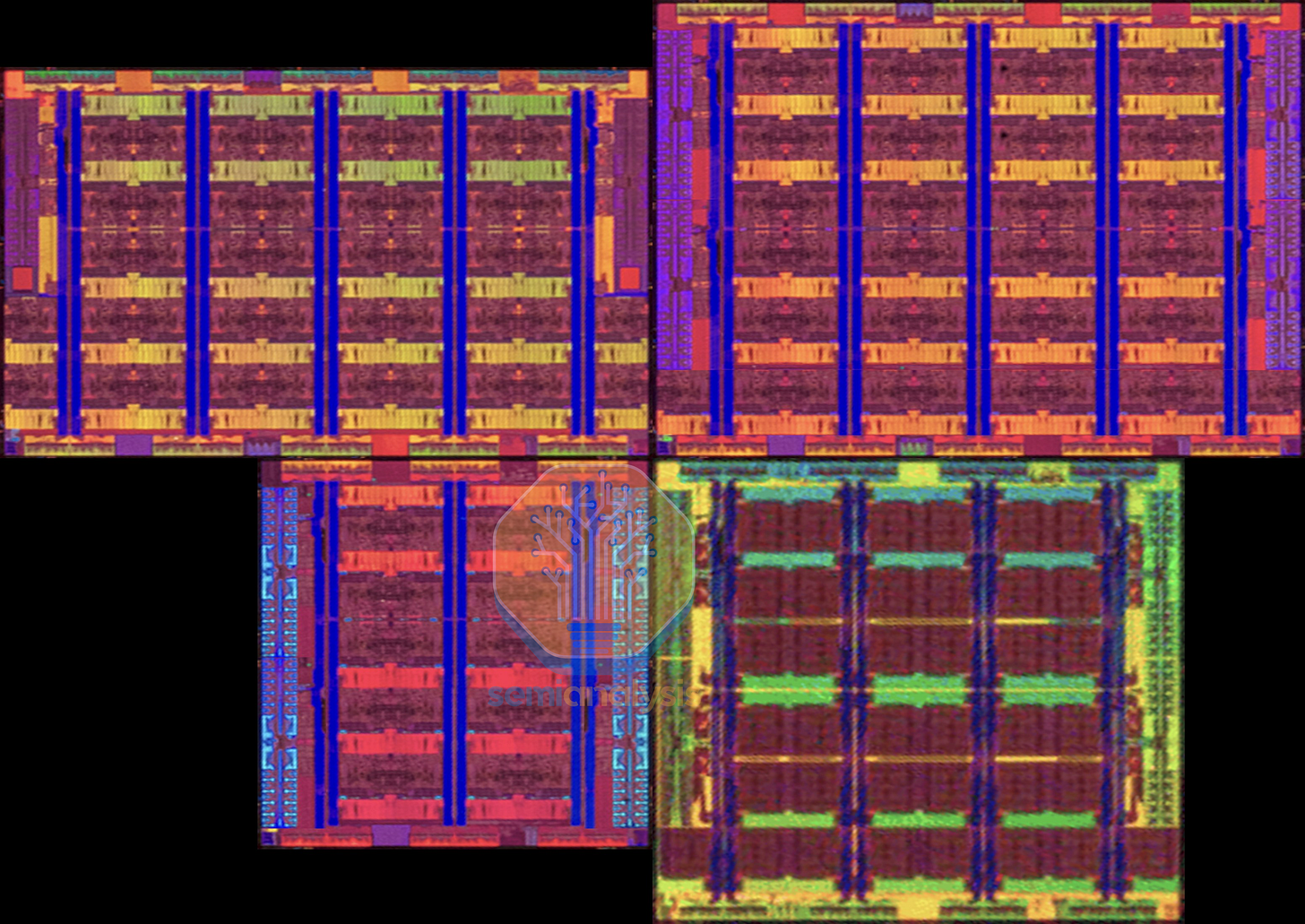
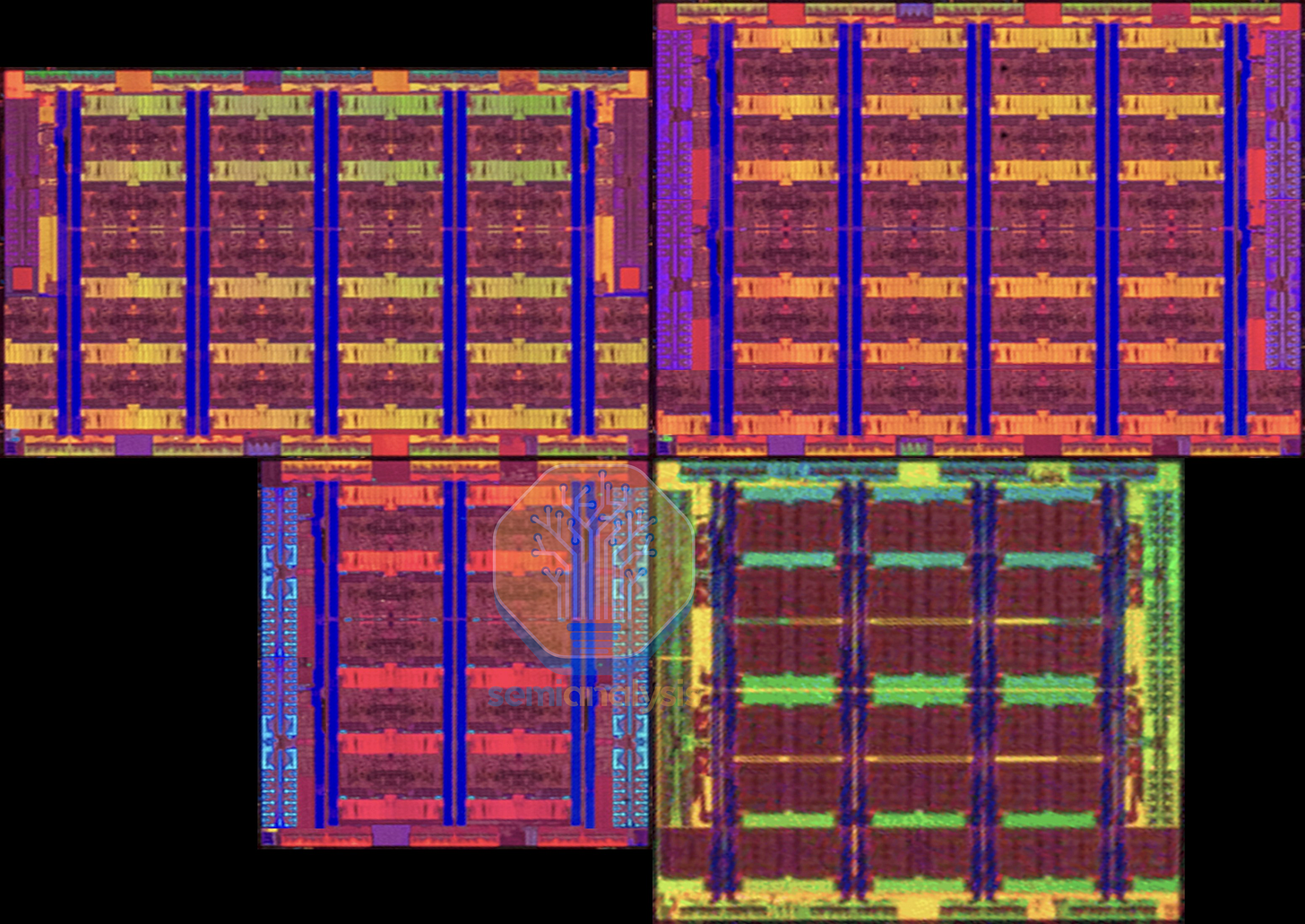
在拥有 144 个核心的 Sierra Forest 处理器中,E 核心被分组为 4 核集群,共享一个公共的网状结构,以 8x6 的网格排列,共印刷了 152 个核心,最多可激活 144 个核心。尽管 Sierra Forest 是应超大规模数据中心的需求而开发的,旨在提供一款具有更低单核总拥有成本的“云原生”CPU,但英特尔承认其市场接受度有限。超大规模数据中心已经采用 AMD 的产品并自行设计基于 ARM 架构的 CPU,而英特尔的传统企业客户对此并不感兴趣。因此,双芯片 288 核的 Sierra Forest-AP(Xeon 6900E)SKU 未能实现全面上市,仅作为低产量的非路线图产品存在,以满足少数订购该产品的超大规模数据中心客户的需求。
克利尔沃特森林火灾


这些 I/O 芯片也将在即将推出的 Xeon 6+ Clearwater Forest-AP E-core 处理器中重复使用。计算芯片首次采用了英特尔的 Foveros Direct 混合键合技术,将 18A 核心芯片堆叠在包含网状结构、L3 缓存和内存接口的基础芯片上,使核心数量达到 288 个。垂直分离技术使得计算核心能够采用最新的 18A 逻辑工艺,同时保留在旧款英特尔 3 节点上扩展性不佳的网状结构、缓存和 I/O 芯片。
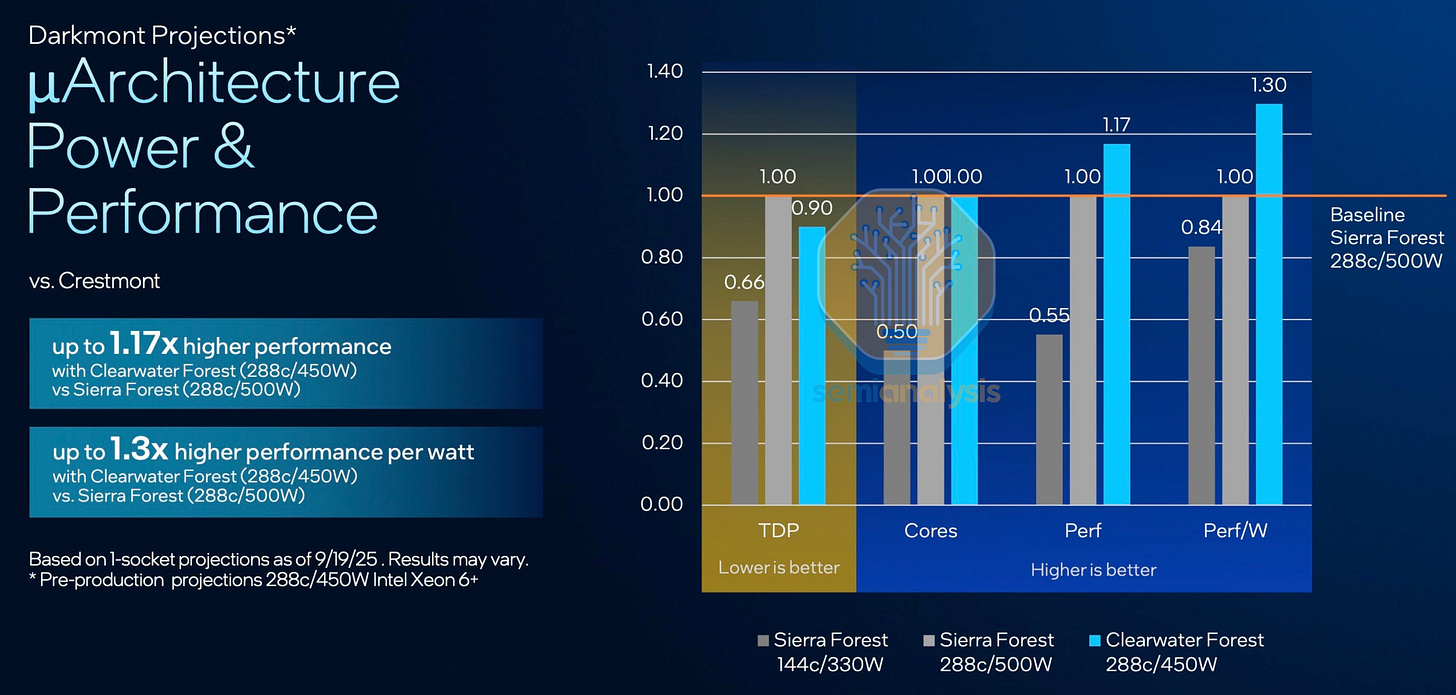
然而,英特尔在 Clearwater Forest 芯片的执行问题再次浮出水面,导致其上市时间从 2025 年下半年推迟至 2026 年上半年。英特尔将延迟归咎于 Foveros Direct 集成方面的挑战,考虑到这款复杂的服务器芯片是
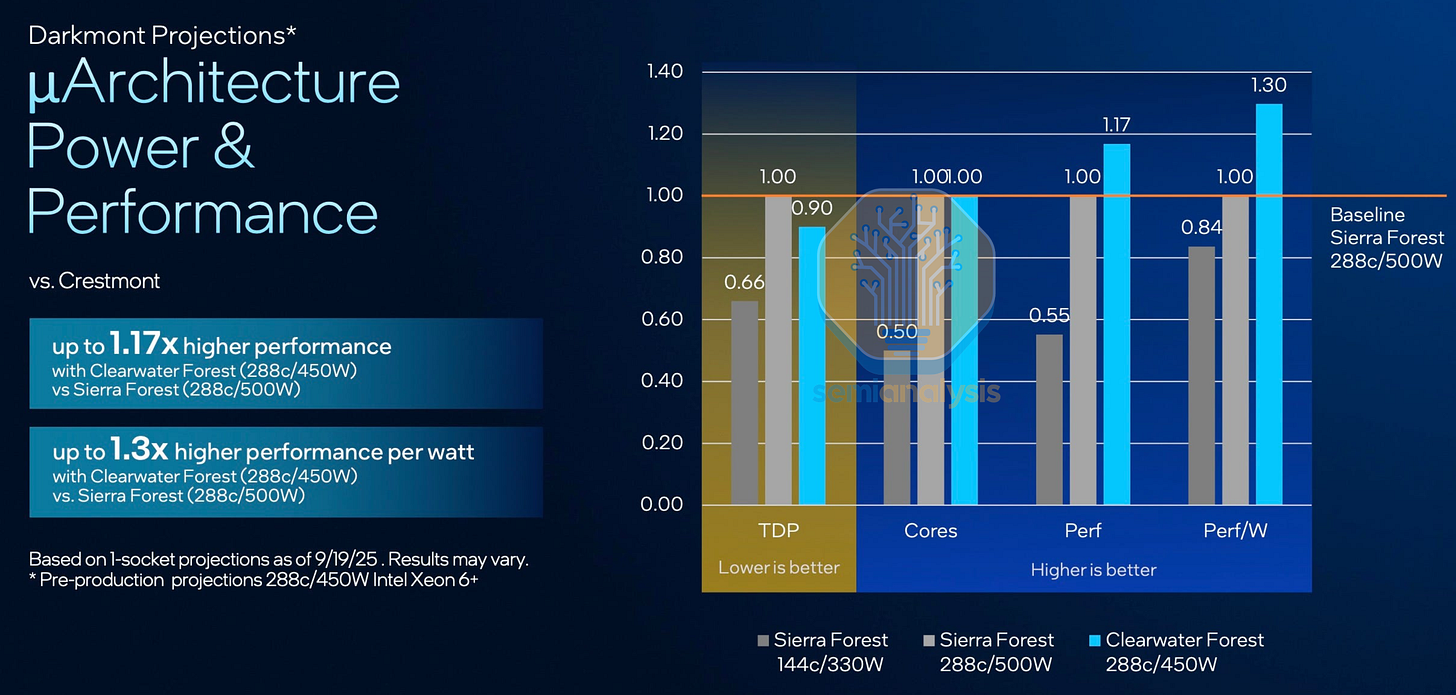
增加,而性能提升却如此有限,难怪英特尔在最新的 2025 财年第四季度财报中几乎没有提及 Clearwater Forest。我们认为,英特尔并不想大规模生产这些芯片,以免损害利润,而是希望将其作为 Foveros Direct 的良率学习工具。
AMD Zen 互连架构

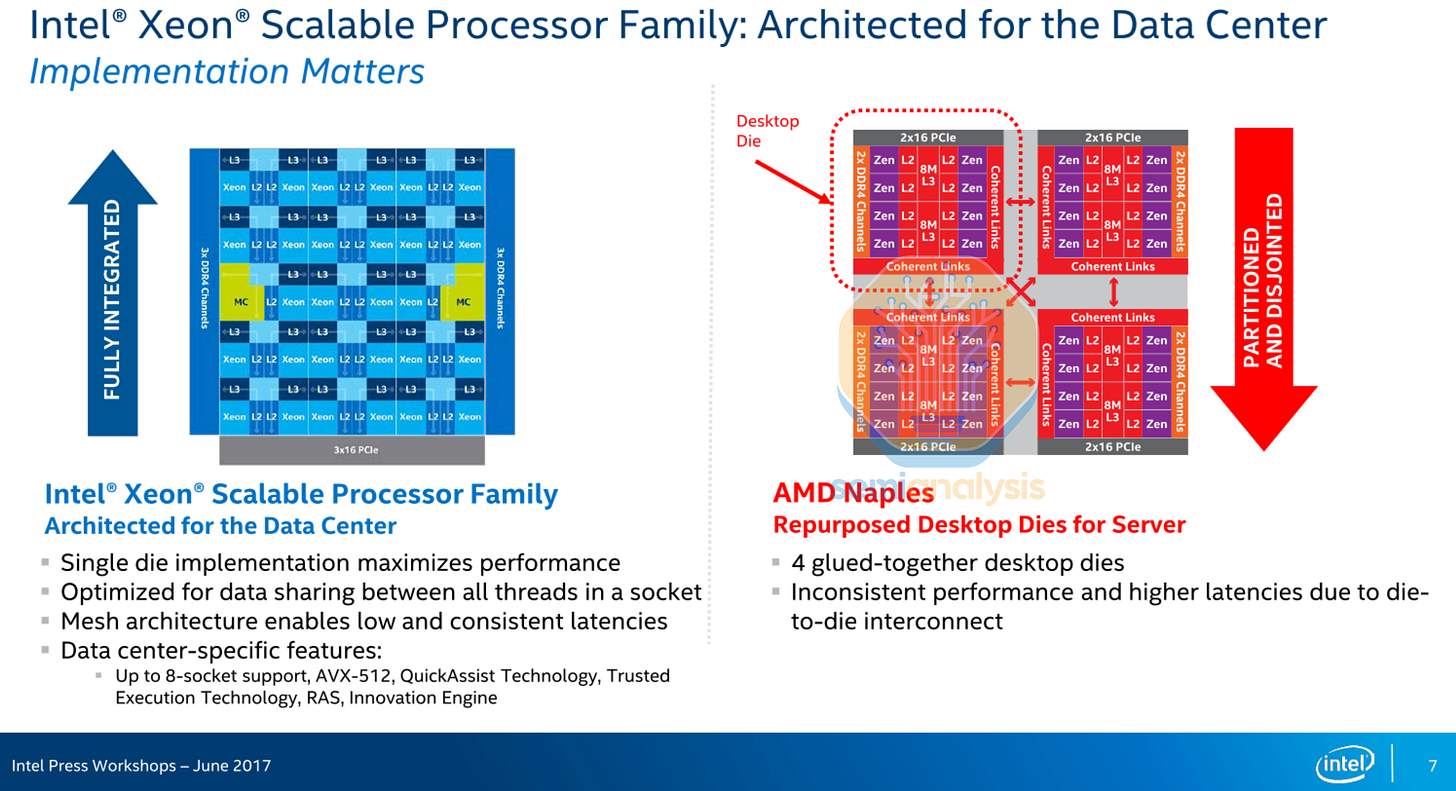
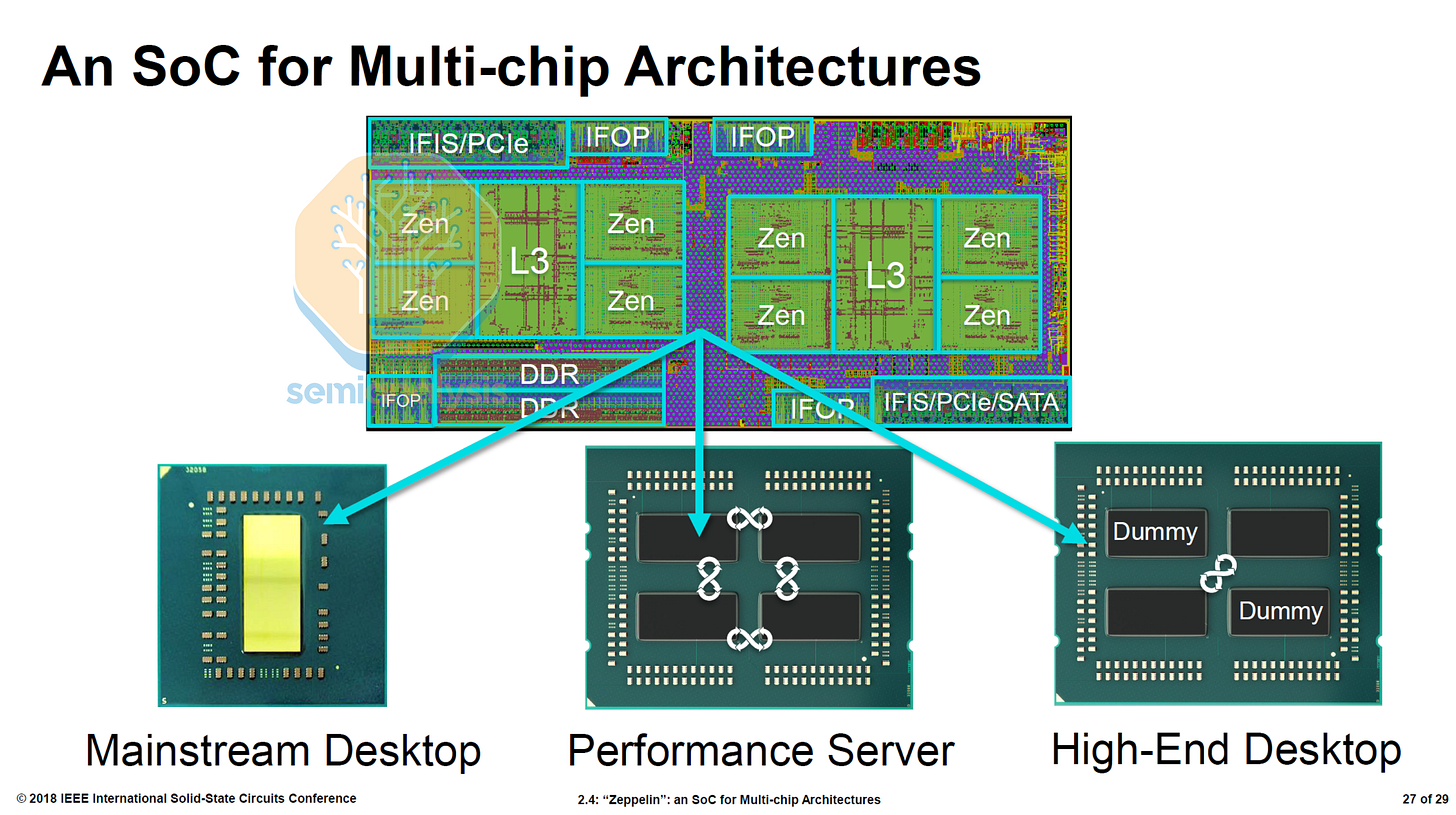
2017 年,AMD 携 EPYC Naples 7001 系列重返数据中心 CPU 市场,引起了不小的轰动。英特尔嘲讽其设计是“四颗粘在一起的桌面芯片”,性能不稳定。但实际上,AMD 的小型设计团队不得不另辟蹊径,他们只能生产单颗芯片,这颗芯片必须同时用于桌面电脑、服务器,甚至还要集成 10Gb 以太网,全部集成在同一颗芯片上。
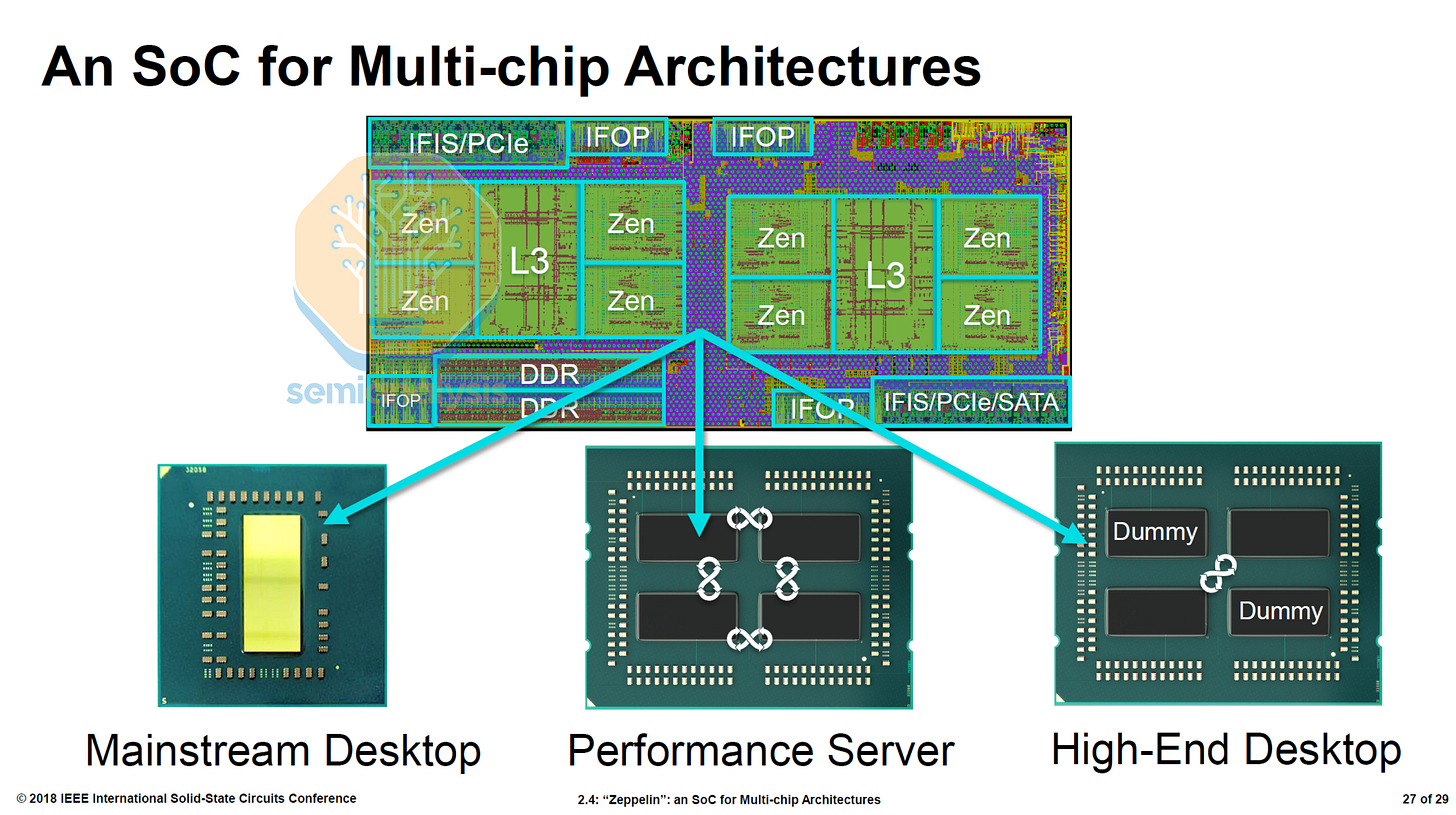
那不勒斯设计局采用了四芯片 MCM,每个“齐柏林”芯片包含 8 个核心,使 AMD 的核心数超过了英特尔的 28 个核心,达到 32 个。每个芯片包含 2 个核心复合体(CCX),

了英特尔“性能不稳定”的批评。
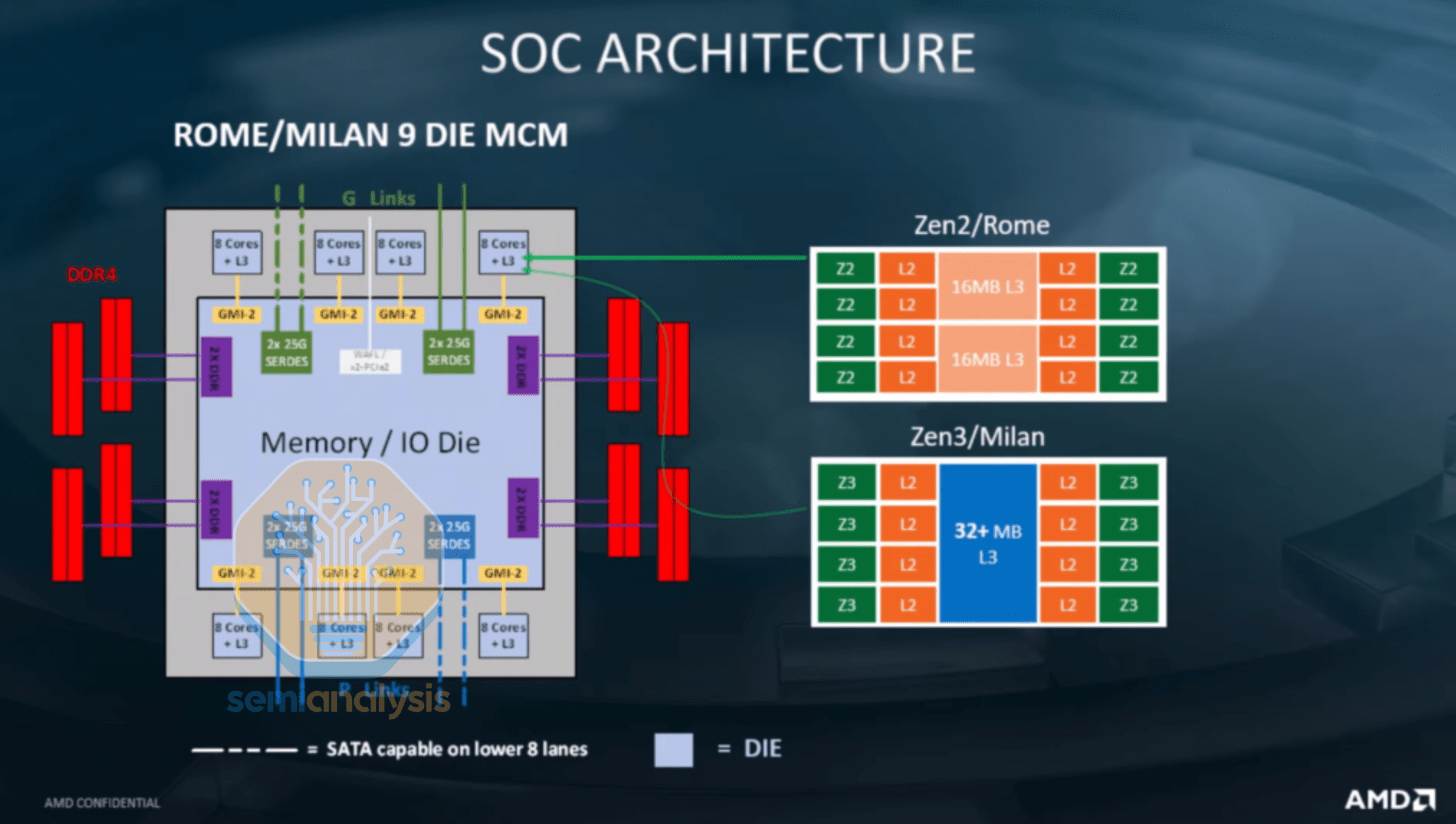
EPYC 罗马的集中式 IO
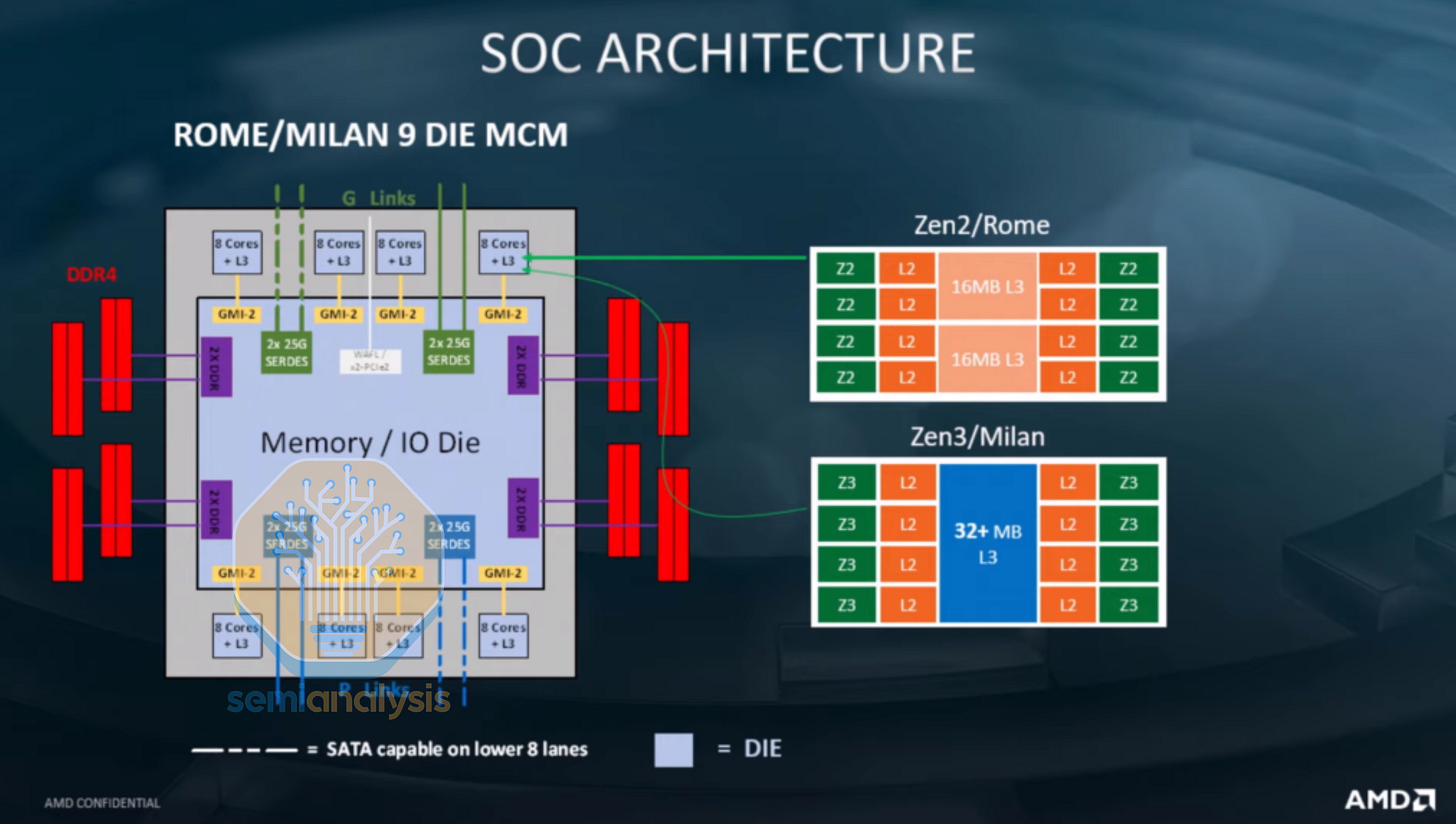
2019 年的 Rome 架构对芯片布局进行了彻底的重新设计,利用异构解耦技术打造出 64 核处理器,远超当
片通信造成的性能损失。2021 年推出的 Milan 架构解决了这个问题,它通过采用环形总线架构,将 CCX 容量增加到 8 个核心,同时沿用了与 Rome 架构相同的 I/O 芯片。

尽管最初计划采用先进的封装技术,但 AMD 在接下来的两代产品中仍然坚持了这种熟悉的设计,2022 年的 Genoa 将采用 12 个 CCD,而 2024 年的 Turin 在 128 核 EPYC 9755 上最多采用 16 个 CCD,所有这些都围绕着一个中央 I/O 芯片,并配备了升级的 DDR5 和 PCIe5 接口。
这种芯片组设计的关键优势在于只需一次芯片流片即可实现核心数量的可扩展性。AMD 只需设计一个 CCD,即可通过包含不同数量的 CCD,为整个 SKU 产品线提供全系列的核心数量。每个 CCD 的小芯片面积也有助于提高良率,并在迁移到新的工艺节点时加快产品上市速度。这与使用大尺寸光罩芯片的网状设计形成鲜明对比,后者需要为每种核心数量进行多次流片,而网状设计则使用较小的芯片。不同的 CCD 设计也可以在共享同一 I/O 芯片和插槽平台的情况下进行替换,AMD 还创建了其他变体,例如在 Bergamo 中使用紧凑型 Zen 4c 核心,以及在 192 核心的 Turin 版本中使用 Zen 5c 核心。我们曾在此撰文介绍过这种用于高效云计算的新核心变体。此外,这种解耦设计还允许使用 EPYC 8004 Siena 处理器,在 6 通道内存平台上仅使用 4 个 Zen 4c CCD,从而制造出
器(QAT、DLB、IAA、DSA)。
有趣的是,芯片间的互连似乎不再需要 EMIB 高级封装,而是通过封装基板上的长走线将每个 CBB 芯片连接到两个 IMH 芯片,从而使每个 CBB 可以直接访问整个内存和 I/O 接口,而无需通过额外的跳转连接到另一个 IMH。这也确保了任何 CBB 之间的通信只需要两次跨芯片跳转。由于放弃了高级封装并将内核分散到 4 个芯片上,我们预计跨 CBB 的延迟会显著增加,与保持在同一芯片内相比,延迟差异会很大。
尽管延迟过高是个问题,但 Diamond Rapids 最大的问题在于缺少 SMT(同步多线程)。由于 Spectre 和 Meltdown 漏洞对英特尔的影响远大于 AMD,英特尔的核心设计团队开始在设计 P 核时摒弃 SMT,最早应用于 2024 年面向客户端 PC 的 Lion Cove 架构。当时英特尔的解释是,移除 SMT 功能节省的面积可以提升效率,但会牺牲原始吞吐量。这对于 PC 设计来说并无大碍,因为他们同时集成了 E 核,可以增强多线程性能。
然而,对于数据中心 CPU 而言,最大吞吐量至关重要,这严重限制了 Diamond Rapids 的性能。与目前 128 核 256 线程的 Granite Rapids 相比,我们预计主打的 192 核 192 线程的 Diamond Rapids 速度仅提升约 40%,这意味着英特尔在下一代产品中仍将面临性能落后于 AMD 的局面。
英特尔在最后时刻彻底取消了主流的 8 通道 Diamond Rapids-SP 平台,这意味着其销量最大的核心市场至少在 2028 年之前都将没有新一代产品。虽然这有助于精简英特尔臃肿的产品线,但我们认为这是一个错误的决定,因为用于人工智能工具和上下文存储的通用计算需要的是具有良好连接性的主流 CPU,而不是单路性能极高的处理器。
AMD Venice 架构变更
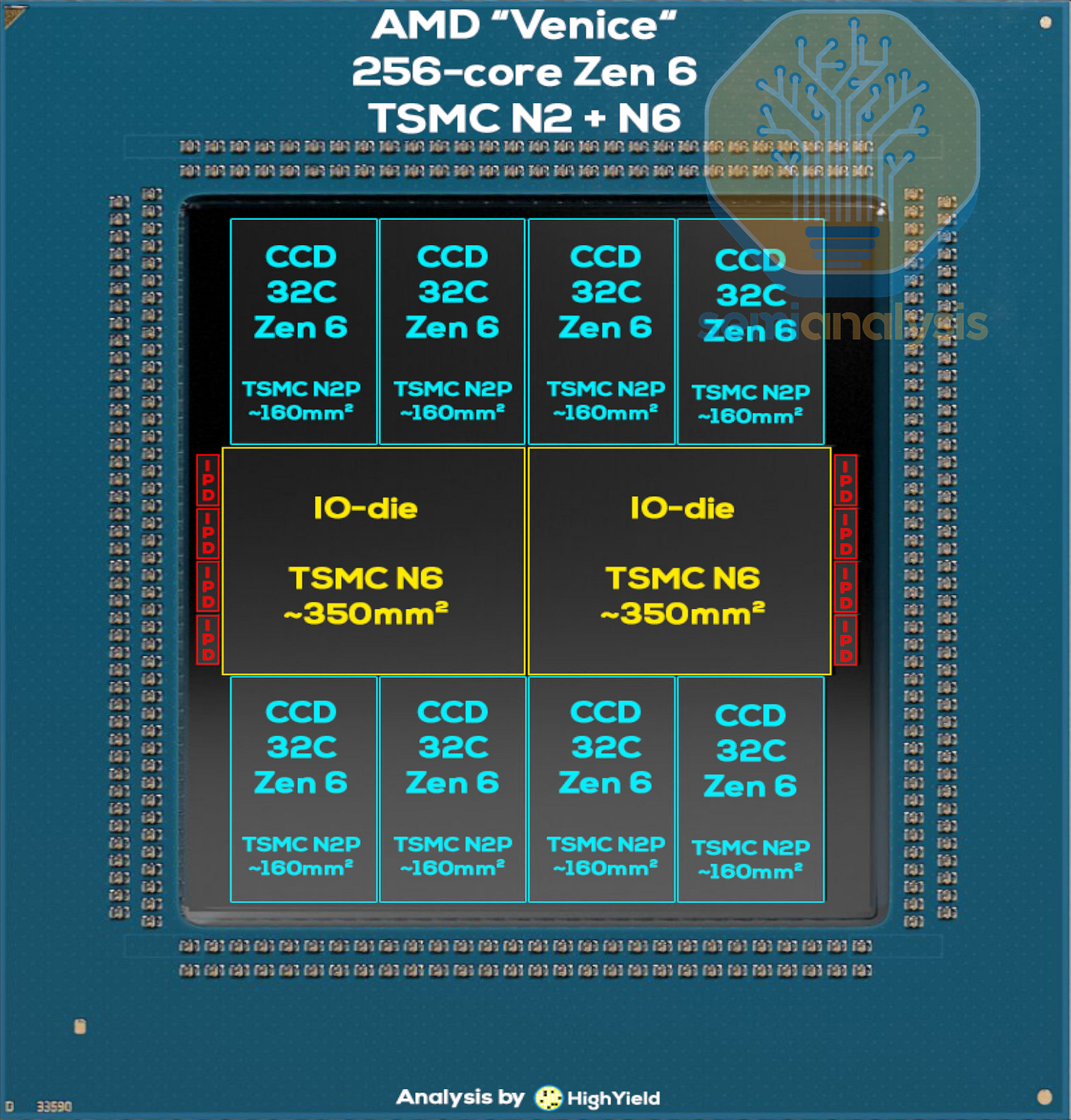
英特尔放弃了 EMIB 技术,而 AMD 最终在 Venice 芯片上采用了与之类似的先进封装技术,并使用高速短距离链路将 CCD 芯片连接到 I/O 芯片。我们的加速器、HBM 和先进封装模型已具备相应的产能。
CCD 链路所需的额外海岸线占用了额外的宽度,因此中央 I/O 集线器必须分成两个芯片。这导致芯片间需要进行额外的跳转才能跨越芯片的不同

核心以提高良率。八个台积电 N2 CCD 芯片使核心数量达到 256 个,比 192 核心的 Turin-Dense 3nm 工艺 EPYC 9965 增加了三分之一。Zen6c 处理器每个核心配备了完整的 4MB L3 缓存,而 Zen5c 处理器则将 L3 缓存减半,从而在每个 CCD 芯片上形成了 128MB 的大容量缓存区域。
针对 AI 头部节点,核心数量和频率都经过优化的“-F”系列产品将采用与消费级桌面和移动 PC 产品线相同的 12 核 Zen6 CCD 设计,最多可在 8 个 CCD 中实现 96 个核心。虽然这相比 128 核的 Turin-Classic 4nm EPYC 9755 有所退步,但其核心数量比高频 64 核 EPYC 9575F 多了 50%。
最后,在 DDR5 接口出口附近的 I/O 芯片旁边可以看到 8 个小型芯片。这些是集成被动器件(IPD),它们有助于在 I/O 密集区域平滑地为芯片供电,因为在该区域,SP7 封装的布线因内存通道扇出而饱和。
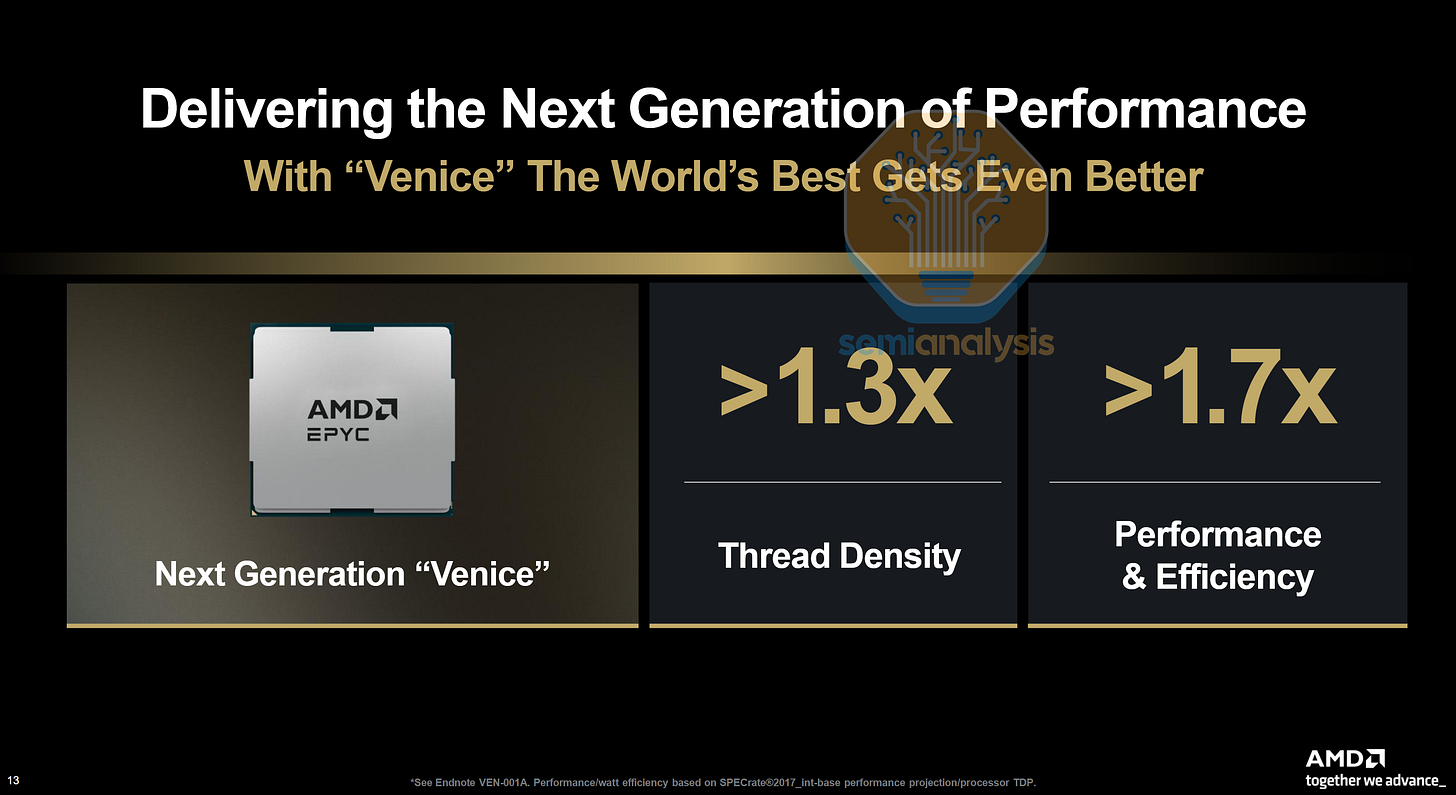
在性能方面,AMD 声称,在 SPECrate®2017_int_base 测试中,顶级 256 核版本的每瓦性能比顶级 192 核 Turin 版本高出 1.7 倍以上,这意味着得益于全新的 Zen 6 核心微架构和更高的每时钟周期指令数 (IPC),每个核心的性能也更高。
M 的要求,因此我们认为该指令的应用范围将受到限制。
由于 AMD 的单核性能已经远超英特尔(96 核的 Turin 处理器性能与 128 核的 Granite Rapids 处理器相当),AMD Venice 与英特尔 Diamond Rapids 之间的性能差距在 2026 至 2028 年这一代数据中心 CPU 中将会进一步扩大。得益于全新的芯片间互连技术和更大的核心域,Venice 的核间延迟应该会比 Turin 有所降低。
AMD 正在加倍投入英特尔撤出的业务领域。英特尔取消了其 8 通道处理器项目,而 AMD 将推出全新的 8 通道 Venice SP8 平台,作为低功耗、小尺寸插槽处理器 EPYC 8004 Siena 系列的继任者,同时仍将提供高达 128 个高密度 Zen 6c 核心。凭借此举,AMD 将在企业级市场(英特尔的传统优势市场)获得大幅份额。
2026 年 CPU 成本分析
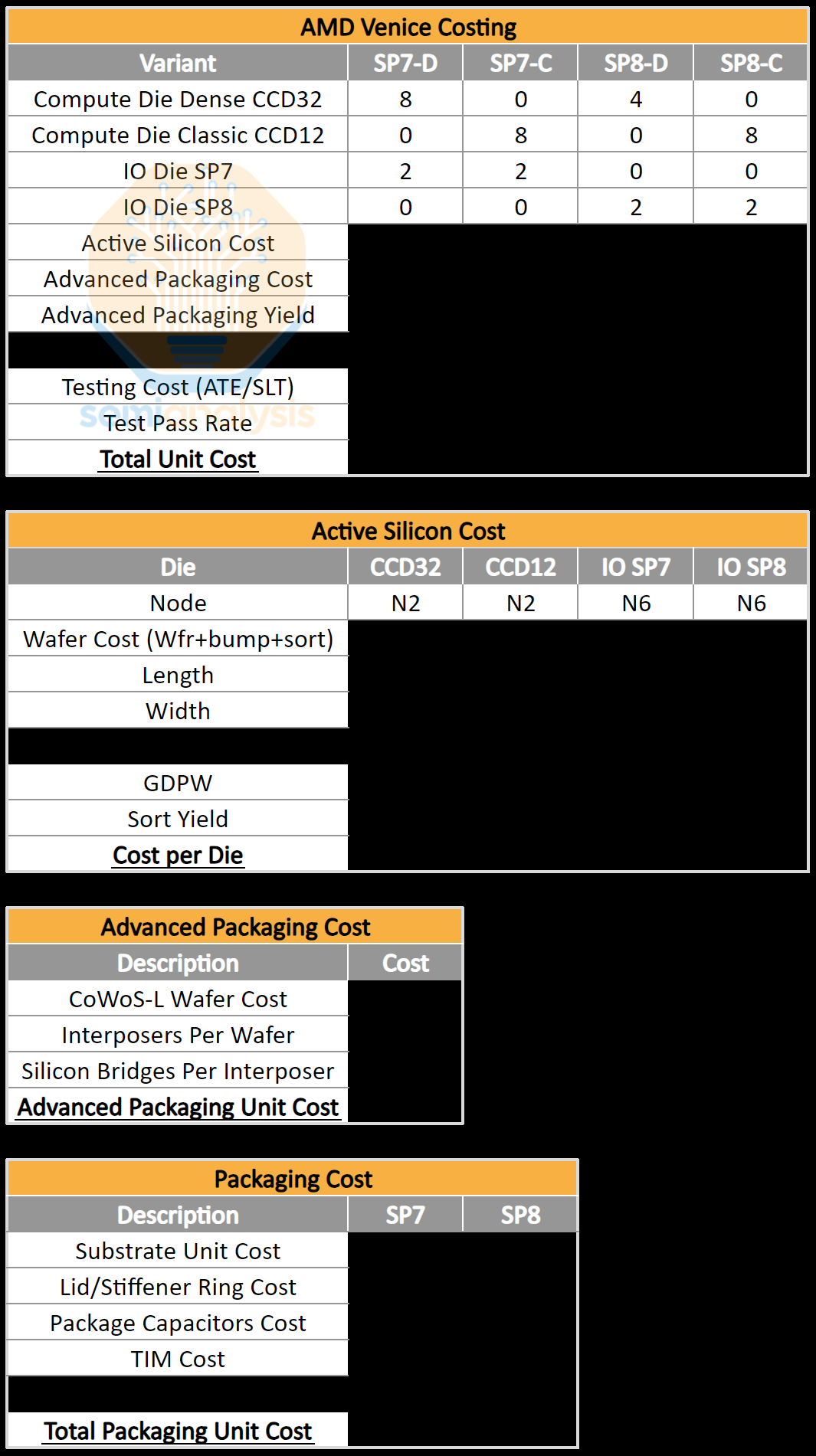
SemiAnalysis 基于我们对供应链的深入了解,提供详细的物料清单成本分析。如需了解芯片的具体尺寸、配置、拓扑结构、性能预估以及与超大规模 ARM CPU 的竞争优势,请联系 [email protected],我们将为您提供定制化的咨询和竞争分析服务。我们拥有 AMD Turin、Venice、Intel Granite Rapids、Diamond Rapids、NVIDIA Grace、Vera 以及来自 AWS、Microsoft、Google 等公司的超大规模 ARM CPU 的详细成本分析和细分数据。
Nvidia Grace
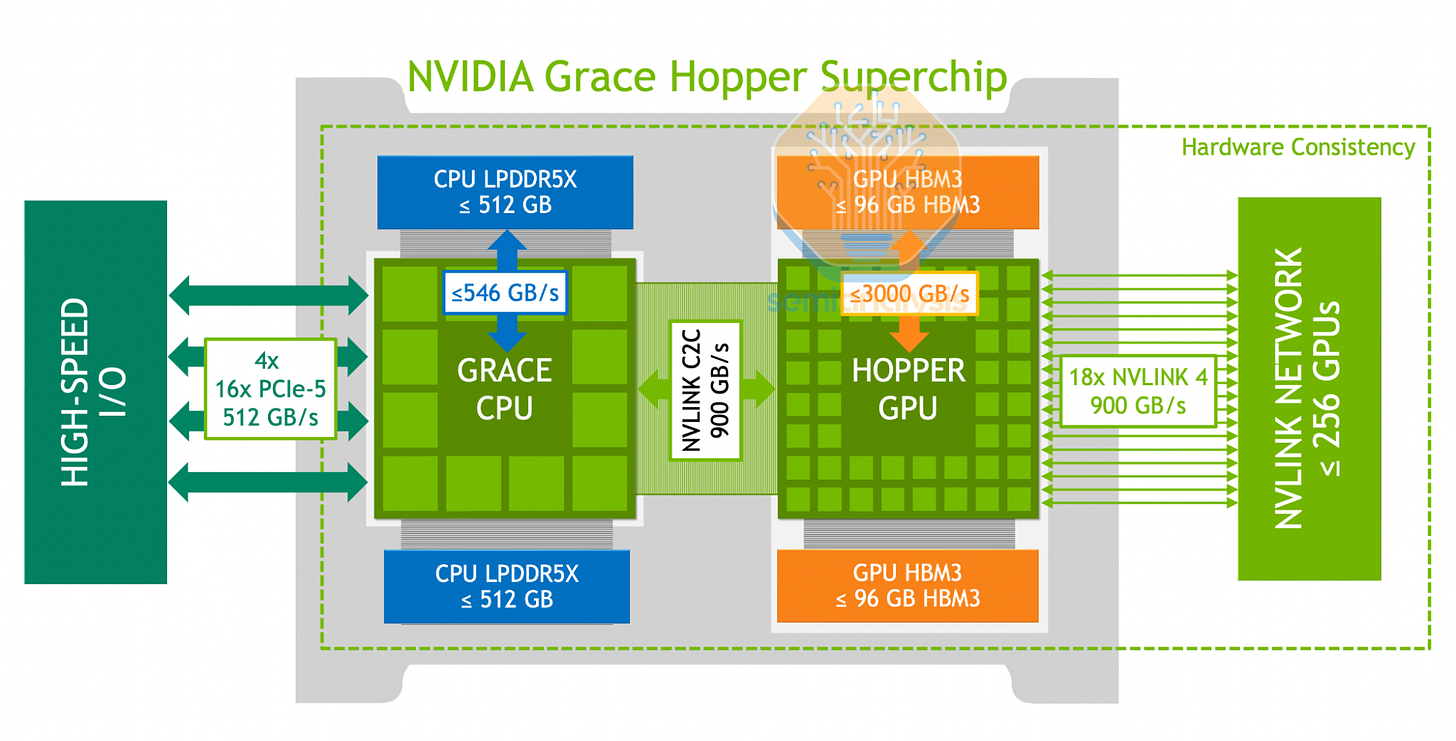
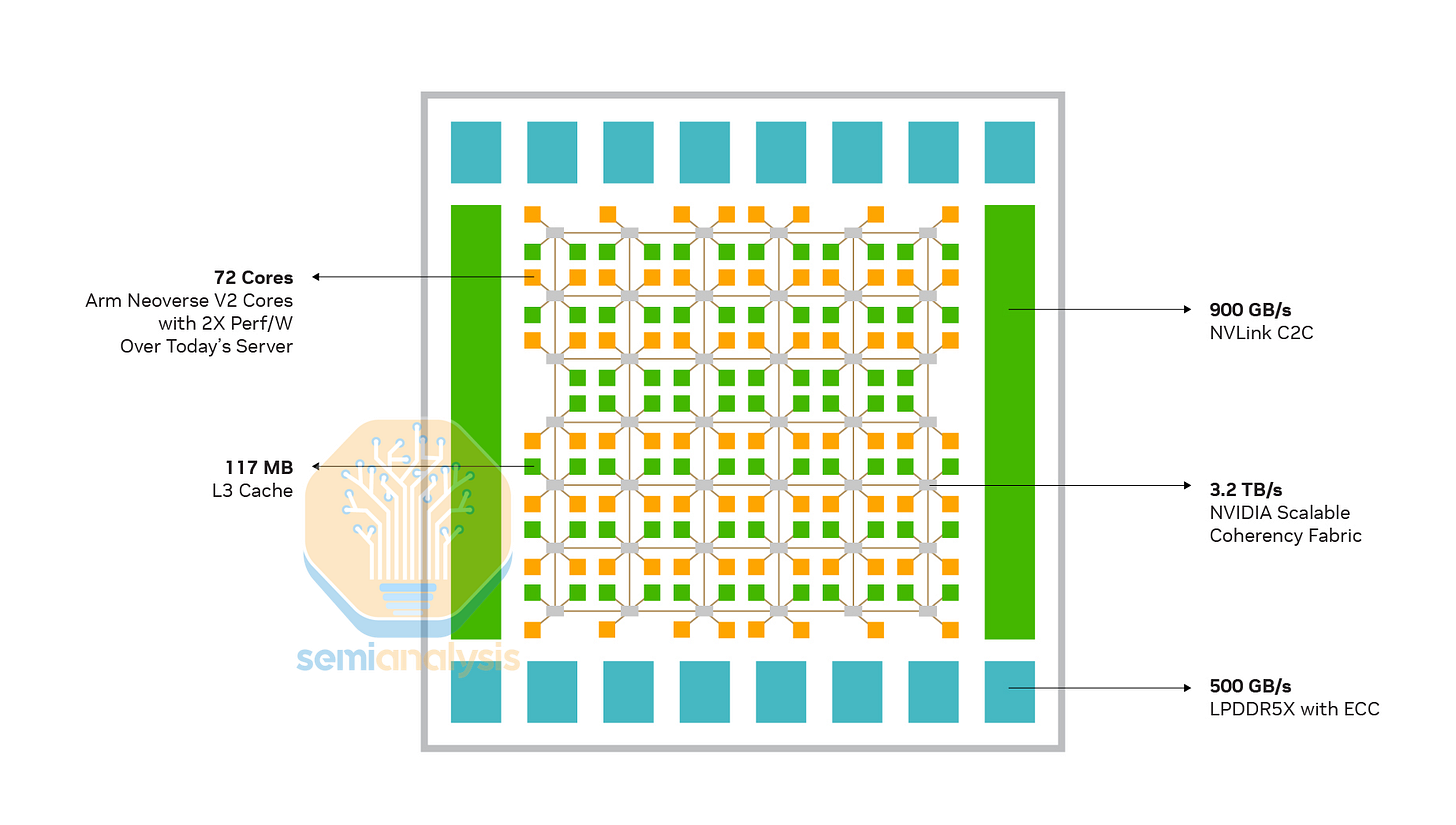
与本文介绍的大多数通用 CPU 不同,NVIDIA 的 CPU 在设计之初就充分考虑了核心节点和扩展 GPU 内存(EMAC)的需求,而 NVLink-C2C 则是其核心技术。这条 900GB/s(双向)高速链路允许连接的 Hopper 或 Blackwell GPU 以全带宽访问 CPU 的内存,从而缓解了 HBM 内存容量不足的限制,每个 Grace CPU 最高可配备 480GB 内存。Grace 还采用了移动级 LPDDR5X 内存,在保持 512 位宽内存总线上 500GB/s 高带宽的同时,有效降低了非 GPU 组件的功耗。最初的 Grace Hopper 超级芯片为每个 GPU 配备了一颗 Grace CPU,而后来的 Grace Blackwell 系列则实现了两颗 GPU 共享一颗 CPU。NVIDIA 还为需要高内存带宽的高性能计算(HPC)客户提供了双 Grace 超级芯片 CPU。
在 CPU 核心方面,NVIDIA 采用了高性能的 ARM Neoverse V2 设计,配备 1MB
性能计算 (HPC) 代码时速度较慢。根据英伟达的 Grace 性能调优指南 ,优化大型应用程序以提高代码局部性可以带来 50% 的速度提升。这是由于核心分支预测引擎在存储和提取即将使用的指令方面存在局限性。在 Grace 架构中,指令被组织成 32 个 2MB 的虚拟地址空间。
当分支目标缓冲区填充超过 24 个区域时,性能会急剧下降,因为热代码会占用缓冲区并增加指令切换频率,导致更多分支预测错误。如果程序超过 32 个区域,则整个 64MB 缓冲区将被清空,分支预测器会忘记所有先前的分支指令以适应新的指令。如果没有正常工作的分支预测器,CPU 内核的前端将成为整个运行的瓶颈,因为 ALU 会处于空闲状态等待指令执行。
这就是为什么 GB200 和 GB300 中的 Grace CPU 目前会降低 AI 工作负载的速度。
英伟达 Vera
Vera 将于 2026 年在 Rubin 平台上进一步提升性能,将 C2C 带宽翻倍至 1.8TB/s,并将内存宽度翻倍,配备八个 128 位宽的 SOCAMM 192GB 模块,内存容量达到 1.5TB,带宽为 1.2TB/s。网状架构得以保留,采用 7x13 网格,容纳 91 个核心,最多可激活 88 个核心。L3 缓存容量增加至 162MB。NVIDIA 现在将外围内存和 I/O 区域分离到独立的芯片组中,总共包含 6 个采用 CoWoS-R 封装的芯片(1 个采用 3nm 工艺的 NVLink-C2C 计算芯片,4 个 LPDDR5 内存芯片和 1 个 PCIe6/CXL3 I/O 芯片)。
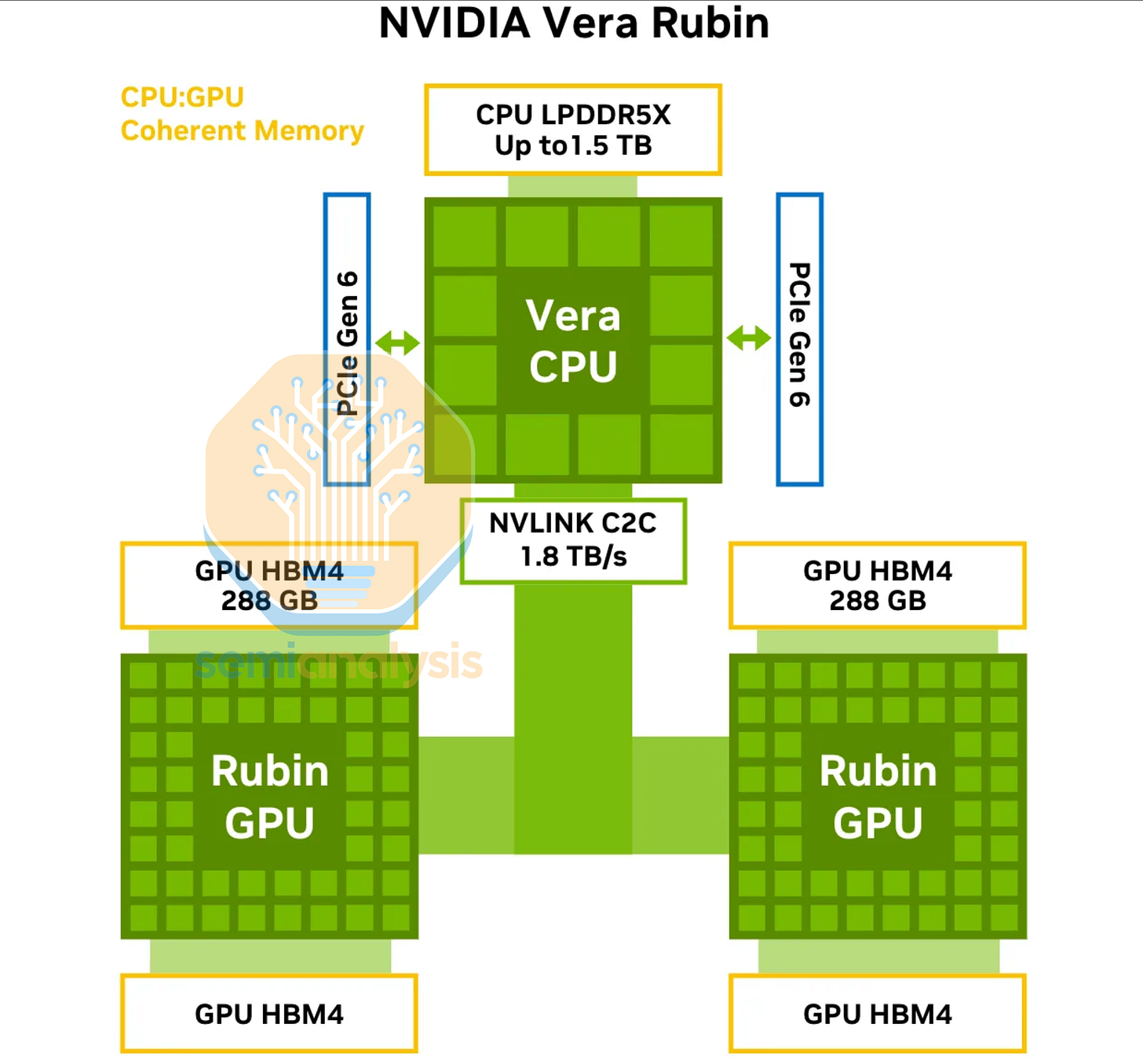


或许是受够了 ARM Neoverse 核心的性能瓶颈,NVIDIA 重新组建了其定制 ARM 核心设计团队,并推出了支持 SMT(同步多线程)的全新 Olympus 核心,实现了 88 个核心、176 个线程的架构。NVIDIA 上一次推出定制核心还是在 8 年前的 Tegra Xavier SoC 中,当时使用的是 10 个 Carmel 核心。ARMv9.2 Olympus 核心将浮点单元的端口宽度从 Neoverse V2 的 4 个增加到 6 个 128 位端口,并且现在支持 ARM 的 SVE2 FP8 运算。每个核心都配备了 2MB 的私有 L2 缓存,是 Grace 核心的两倍。NVIDIA 声称,Vera 处理器的整体性能提升了 2 倍。
AWS Graviton5
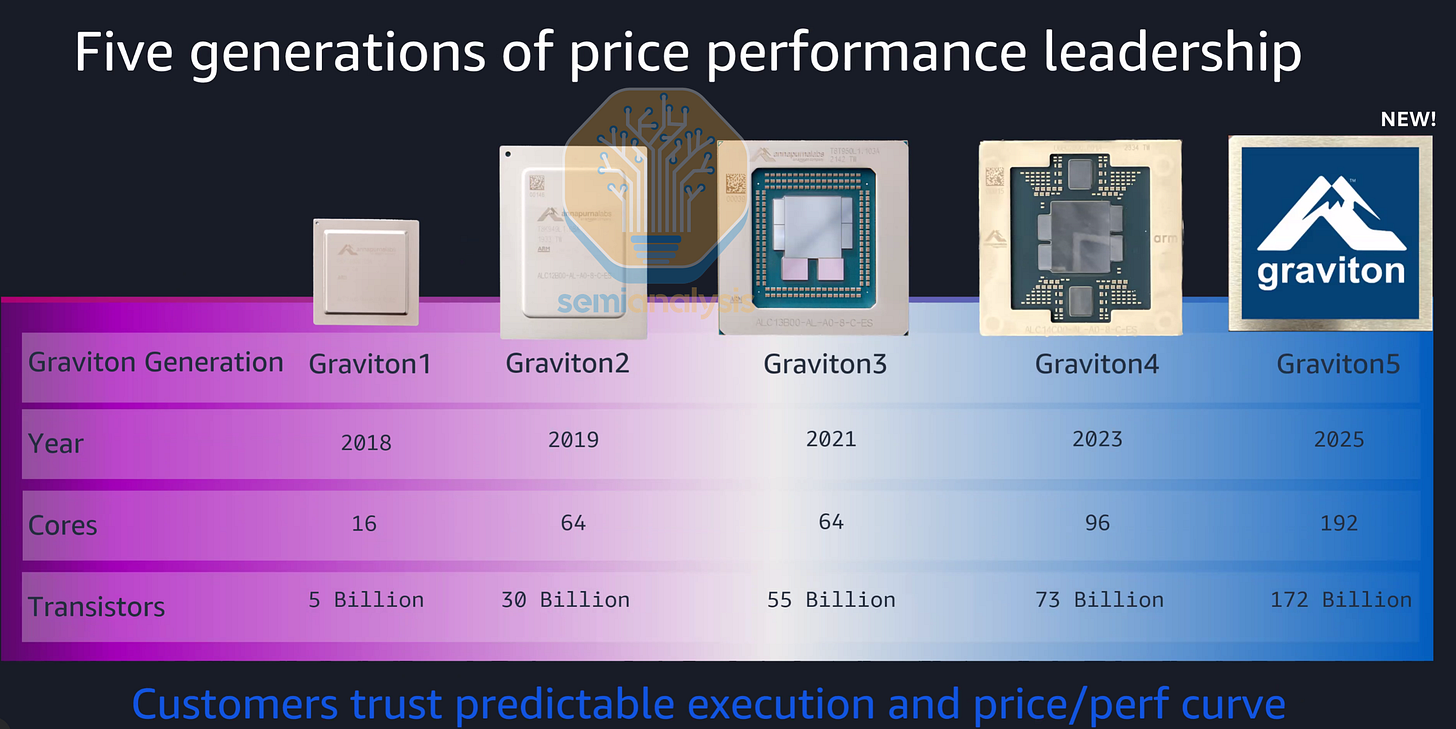
亚马逊云服务 (AWS) 是首家成功开发并部署自有云端 CPU 的超大规模云服务提供商。得益于收购 Annapurna Labs 芯片设计团队和 ARM 的 Neoverse 计算子系统 (CSS) 参考设计,AWS 现在能够以更低的价格提供 EC2 云实例,这得益于其直接与台积电和 OSAT 合作伙伴合作进行芯片生产,而非采购英特尔至强处理器,从而获得了更高的利润率。
Graviton 的推广真正开始于新冠疫情期间的云计算热潮,当时 AWS 推出了 Graviton2 架构,并提供大幅折扣以吸引云客户将其程序从 x86 架构迁移到 ARM 生态系统。虽然与英特尔 Cascade Lake 架构相比,Graviton2 的单核性能略逊一筹,但它以更低的价格提供了 64 个 Neoverse N1 核心,并且性价比更高。
Graviton3 在 2021 年底的预览版中进行了多项改进,旨在将单核性能提升至具有竞争力的水平。AWS 采用了 ARM 的 Neoverse V1 核心,这是一款体积更大的 CPU 核心,其浮点运算性能是 N1 的两倍,同时保持核心数量为 64 个。它采用了 10x7 核心网状网络 (CMN),芯片上印制了 65 个核心,并预留了一个用于分拣的禁用核心。AWS 还将设计拆分为多个芯片组,在台积电 N5 芯片上,围绕着中央计算核心分布了四个 DDR5 内存芯片组和两个 PCIe5 I/O 芯片组,所有芯片组均采用英特尔的 EMIB 先进封装技术连接。由于英特尔 Sapphire Rapids 的延迟发布,Graviton3 成为首批部署 DDR5 和 PCIe5 的数据中心 CPU 之一,比 AMD 和英特尔早整整一年,我们此前曾对Graviton4 继续扩展,采用了升级后的 Neoverse V2 核心,核心数量和内存通道数分别提升了 50%,达到 96 个和 12 个,相比上一代产品速度提升了 30% 至 45%。PCIe 5 通道数也从 32 条增加到 96 条,显著提升了网络和存储连接能力。此外,Graviton4 还支持双路配置,以实现更高的实例核心数。
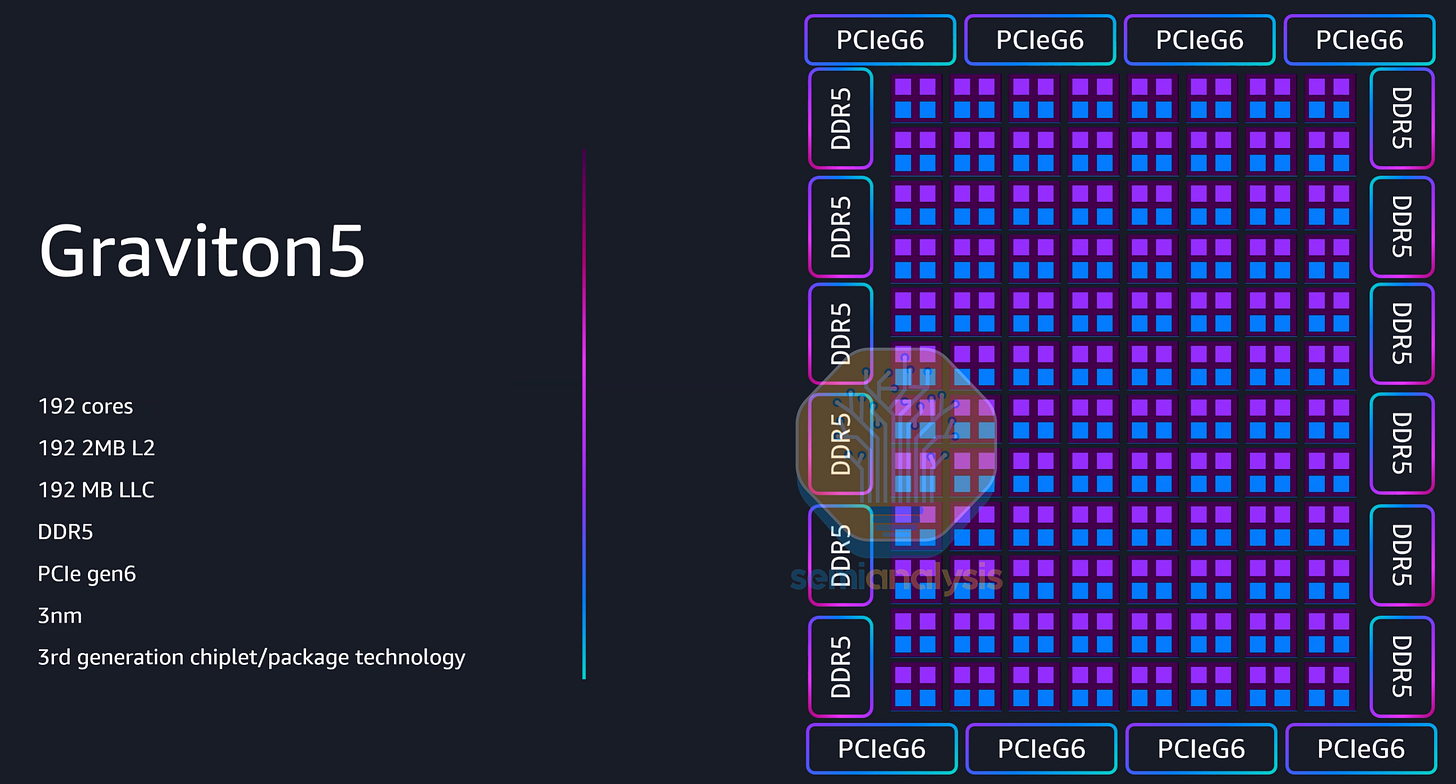
自 2025 年 12 月开始预览以来,Graviton 5 处理器性能再次大幅提升,配备 192 个 Neoverse V3 核心,是上一代的两倍,采用台积电 3nm 工艺制造,晶体管数量高达 1720 亿。虽然每个核心的 L2 缓存仍为 2MB,但共享的 L3 缓存从 Graviton 4 的 36MB 提升至 Graviton 5 的 192MB,这主要得益于额外的缓存作为缓冲,因为尽管核心数量翻了一番,内存带宽(12 通道 DDR5-8800)仅提升了 57%。
正如我们在核心研究中讨论的那样,Graviton 5 的包装非常独特 ,并且对供应链中的一些供应商产生了重大影响。
有趣的是,虽然 PCIe 通道升级到了 Gen6,但通道数量却从 Graviton4 的 96 条减少到了 Graviton5 的 64 条,这显然是因为 AWS 通常不会部署使用所有 PCIe 通道的配置。这种成本优化在不影响性能的前提下,为亚马逊节省了大量的总体拥有成本 (TCO)。
Graviton5 采用改进的芯片组架构和互连方式,两个核心共享同一个网格节点,排列成 8x12 的网格。虽然 AWS 这次没有展示封装和芯片配置,但他们保证 Graviton5 采用了全新的封装策略,并且 CPU 核心网格分布在多个计算芯片上。
在 CPU 使用方面,AWS 自豪地表示,他们已在内部 CI/CD 设计集成流程中使用了数千颗 Graviton CPU,并运行 EDA 工具来设计和验证未来的 Graviton、Trainium 和 Nitro 芯片,从而形成了一个内部“狗粮循环”,即 Graviton 芯片用于设计 Graviton 芯片。AWS 还宣布,他们的 Trainium3 加速器现在将使用 Graviton CPU 作为头节点,配置为 1 个 CPU 对应 4 个 XPU。虽然初始版本使用 Graviton 4,但未来的 Trainium3 集群将采用 Graviton 5。
微软 Cobalt 200

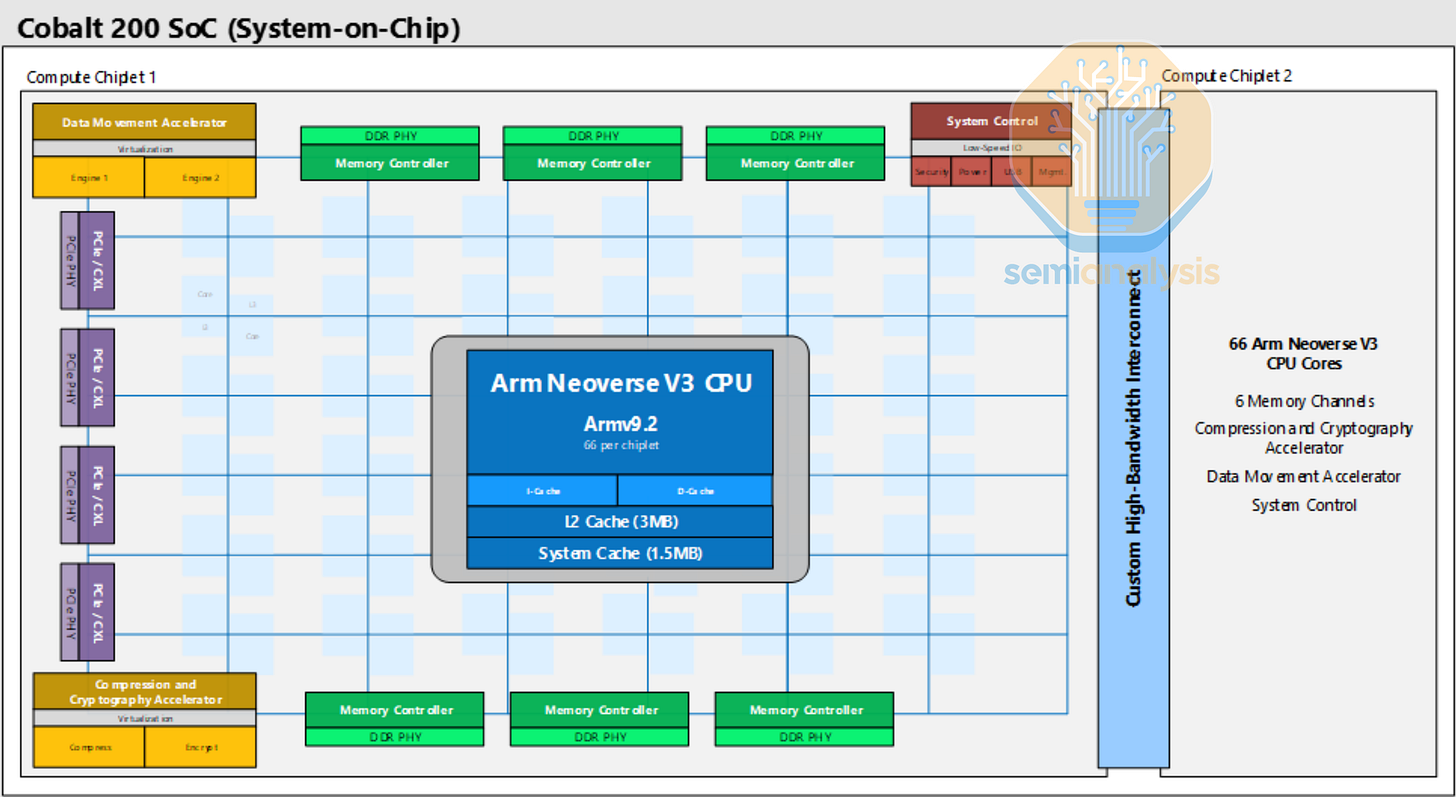
继我们之前报道过的微软首款 Cobalt 100 CPU 于 2023 年发布之后,Cobalt 200 于 2025 年底发布,并进行了多项升级。虽然核心数量增加不多,仅从 128 个增加到 132 个,但与上一代 Neoverse N2 相比,采用 Neoverse V3 设计的每颗核心性能大幅提升。每颗核心都配备了容量高达 3MB 的 L2 缓存,并通过标准的 ARM Neoverse CMN S3 网状网络连接到两颗台积电 3nm 制程的计算芯片上,芯片间采用定制的高带宽互连。从图中可以看出,每颗芯片都采用 8x8 网状结构,包含 6 个 DDR5 内存通道和 64 条支持 CXL 的 PCIe 6 通道。每个网状节点由 2 颗核心共享,每颗芯片共印制 72 颗核心,其中 66 颗用于保证良率。此外,网状结构中还分布着 192MB 的共享 L3 缓存。经过这些升级,Cobalt 200 的速度比 Cobalt 100 提高了 50%。
与 Graviton5 不同,Cobalt 200 仅用于 Azure 的通用 CPU 计算服务,不会用作 AI 头节点。微软的 Maia 200 机架式系统则采用英特尔的 Granite Rapids CPU。
Google Axion C4A、N4A


Axion 系列处理器于 2024 年发布,并于 2025 年正式上市,标志着谷歌正式进军定制芯片 CPU 领域,为其 GCP 云服务提供支持。Axion C4A 实例在标准网状网络上最多可搭载 72 个 Neoverse V2 核心,并配备 8 通道 DDR5 内存和 PCIe 5 接口,所有接口均集成在一块 5nm 单芯片上。根据在 2024 年 Google Cloud Next 大会上展示的 Axion 晶圆特写图片,该芯片似乎以 9x9 网格布局印刷了 81 个核心,预留了 9 个核心用于提高良率。因此,我们认为谷歌为即将于 2025 年底推出的 96 核 C4A 裸机实例设计了一款全新的 3nm 芯片。
为了实现更具成本效益的横向扩展 Web 和微服务,谷歌的 Axion N4A 实例现已推出预览版。该实例采用 64 个性能较低的 Neoverse N3 内核,芯片尺寸更小,从而能够在 2026 年前实现显著的产能提升。Axion N4A 芯片是谷歌采用台积电 3nm 工艺完全定制设计的。随着谷歌将其内部基础设施迁移到 ARM 架构,Gmail、YouTube、Google Play 和其他服务将与 x86 架构的服务器一起运行在 Axion 平台上。未来,谷歌还将设计 Axion CPU,用作其 TPU 集群(为 Gemini 提供动力)的头部节点。
安培一号收购软银
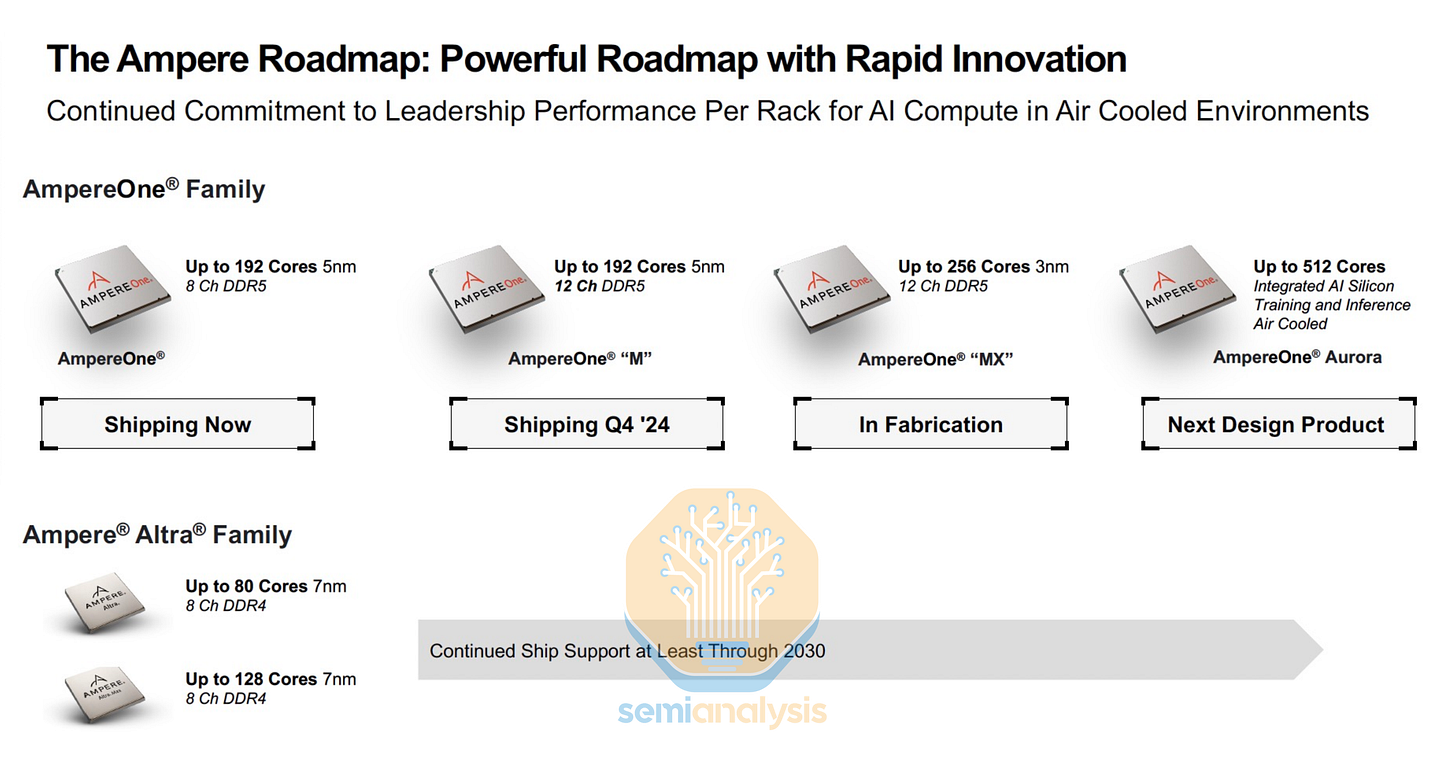


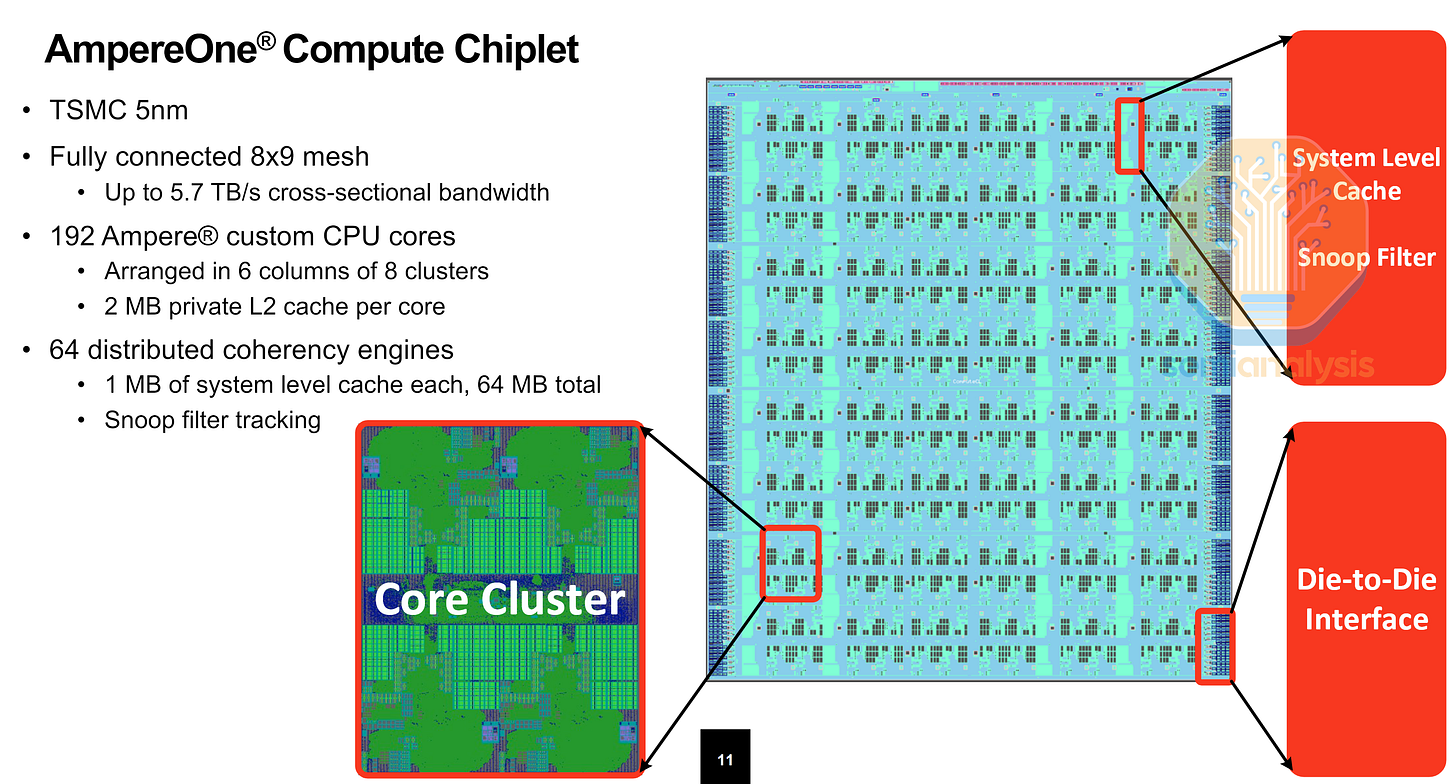
Ampere Computing 是商用 ARM 芯片的先驱,作为 OEM 服务器芯片的第三大供应商,它与 AMD 和 Intel 直接竞争。凭借与 Oracle 的紧密合作,Ampere 隆重推出了 80 核 Altra 和 128 核 Altra Max 系列 CPU,旨在以高性价比的 ARM CPU 打破 x86 CPU 双寡头垄断的局面。Ampere Altra 采用 Neoverse N1 内核,并配备自主研发的网状互连技术,将内核分组为 4 核集群。此外,该 CPU 还集成了 8 通道 DDR4 内存和 128 条 PCIe 4.0 通道,所有组件均集成在一块台积电 7nm 制程芯片上。
下一代 AmpereOne CPU 的核心数量提升至 192 个,这得益于 5nm 制程工艺的改进以及一种新型芯片组设计。该设计将 I/O 分离到独立的 DDR5 和 PCIe 芯片中,并采用 MCM 配置,无需使用中介层。Ampere 还采用了定制的 ARM 内核,该内核的设计目标是提高核心密度而非绝对性能,并配备了容量更大的 2MB L2 缓存,以最大限度地减少因相邻核心上运行的其他虚拟机占用共享网状互连网络流量而造成的性能损失。类似的 4 核集群部署在 9x8 网状网络上。总体而言,其整数运算性能比 Altra Max 提升了一倍。
这种芯片组设计使得同一计算芯片可以在不同的版本中重复使用,例如 12 通道的 AmpereOne-M 就增加了两个内存控制器芯片。未来的 AmpereOne-MX 沿用了相同的 I/O 芯片组,但采用了 3nm 工艺制造的 256 核计算芯片。他们的 2024 年产品路线图还详细介绍了未来将推出的 AmpereOne Aurora 芯片,该芯片拥有 512 个核心,并具备 AI 训练和推理功能。
然而,随着 Ampere Computing 在 2025 年被软银以 65 亿美元收购,这份路线图已不再适用。虽然孙正义确实希望借助 Ampere 的 CPU 设计人才来提升其 Stargate 项目的 CPU 设计水平,但此次收购的另一个重要原因是甲骨文希望剥离业绩不佳的业务。由于时序和执行方面的问题,Ampere 的 CPU 始终未能达到足够高的产量。
Altra 系列是 AMD 首次进军主流市场的力作,但由于当时大多数软件并非 ARM 原生支持,因此上市时间过早,未能实现大规模普及。与能够迅速将内部工作负载适配到自家 ARM 芯片的超大规模数据中心不同,通用和企业级 CPU 市场的转型速度要慢得多。此后,AmpereOne 系列遭遇了多次延期,Oracle Cloud A2 和 CPU 的上市时间推迟到了 2024 年下半年。届时,超大规模数据中心的 ARM CPU 项目已全面展开,AMD 的 CPU 核心数量已与 Ampere 的 192 个核心数量持平,但单核性能却高出 3-4 倍。尽管 Oracle 大力推广 Ampere 实例,并承诺将单核许可费用减半,但这些 CPU 的市场需求依然不足,订单量锐减。Oracle 最终未能用完其预付的 Ampere CPU 款项,其 Ampere CPU 采购额从 2023 财年的 4800 万美元骤降至 2024 财年的 300 万美元,并在 2025 财年进一步跌至 370 万美元。
Ampere 目前在软银旗下从事人工智能芯片和 CPU 的研发工作。
ARM Phoenix
ARM 的核心

然而,ARM 计划在 2026 年更进一步,推出完整的数据中心 CPU 设计方案,Meta 将成为其首个客户。这款代号为 Phoenix 的 CPU 将改变其商业模式,成为芯片供应商,负责从内核到封装的整个芯片设计。这意味着 ARM 将直接与那些获得 Neoverse CSS 架构授权的客户展开竞争。ARM 由软银控股,同时也在为 OpenAI 设计定制 CPU,这是软银与 OpenAI 合资成立的 Stargate OpenAI 项目的一部分。Cloudflare 也正在寻求成为 Phoenix 的客户。我们在 Core Research 报告中详细分析了其成本、利润率和收入 。
Phoenix 采用标准的 Neoverse CSS 设计和布局,与微软的 Cobalt 200 类似。128 个 Neoverse V3 内核通过 ARM 的 CMN 网状网络连接,分布在两颗采用台积电 3nm 工艺制造的半光刻芯片上。在内存和 I/O 方面,Phoenix 配备 12 通道 DDR5 内存,频率为 8400 MT/s,以及 96 条 PCIe Gen 6 通道。其能效也相当出色,CPU TDP 可在 250W 至 350W 之间配置。
凭借此,M
Huawei Kunpeng
中国自主研发 CPU 的步伐仍在稳步推进,龙芯

移动 ARM Cortex 内核。2015 年的 Hi1610 配备了 16 个 A57 内核。2

通过环形总线连接到同一芯片上的四个 DDR4 内存通道,两颗计算芯片共计 8 个内存通道。鲲鹏 920 是首款采用台积电 CoWoS-S 先进封装技术的 CPU,其采用大型硅中介层将两颗计算芯片连接到一颗 I/O 芯片,该 I/O 芯片拥有 40 条 PCIe Gen 4 通道和双集成 100Gb 以太网控制器,并通过定制的芯片间接口实现连接。尽管鲲鹏 920 集成了诸多创新技术,但美国对华为的制裁导致其从台积电的供货中断,打乱了其 CPU 路线图,下一代鲲鹏 930 未能如期在 2021 年发布。

取而代之的是,中芯国际在 2024 年悄然发布了升级版的鲲鹏 920B,并进行了多项改进。其泰山 V120 核心现在支持 SMT(同步多线程),两个计算芯片上各有 10 个集群,每个集群包含 4 个核心,共计 80 个核心和 160 个线程。核心互连和布局与鲲鹏 920 基本相同,计算芯片上配备 8 通道 DDR5 内存。I/O 芯片现在被一分为二,计算芯片位于中间。我们认为 CPU 两代产品之间长达 5 年的间隔是由于美国制裁以及中芯国际需要为 N+2 工艺重新设计芯片所致。


华为计划在 2026 年再次更新其 CPU 产品线,推出鲲鹏 950 处理器,并将其部署在泰山 950 SuperPoD 机架中,用于通用计算。鲲鹏 950 承诺在 OLTP 数据库性能方面比鲲鹏 920B 提升 2.9 倍,这得益于其自主研发的 GaussDB 多写分布式数据库架构。为了实现这一目标,鲲鹏 950 的核心数量翻了一番,达到 192 个,并采用了全新的 LinxiCore 核心,同时保留了 SMT(同步多线程)支持。此外,华为还将推出一款 96 核的较小版本。每个泰山 950 SuperPoD 机架可容纳 16 台双路服务器,并配备高达 48TB 的 DDR5 内存,这意味着其采用了 12 通道内存设计。这些机架还集成了存储和网络功能,将被 Oracle 的 Exadata 数据库服务器采用,并应用于中国金融行业。该设计很可能采用中芯国际(SMIC)的 N+3 工艺制造,该工艺最近也应用于麒麟 9030 智能手机芯片。
华为的路线图将延续到 2028 年,届时将推出鲲鹏 960 系列处理器。这一代产品延续了将处理器设计分为两个版本的趋势。其中,高性能版本拥有 96 个核心和 192 个线程,专为 AI 头节点和数据库应用打造,单核性能有望提升 50%以上;而面向虚拟化和云计算的高密度版本则将核心数量增加到 256 个甚至更多。届时,我们预计华为将在中国超大规模数据中心 CPU 部署市场占据显著份额。
以下我们将介绍我们到 2028 年的 CPU 路线图,并详细阐述 2026 年以后数据中心 CPU 的关键特性和架构变化,包括 AMD 的 Verano 和 Florence、英特尔的 Coral Rapids 和已取消的 CPU 产品线、ARM 的 Venom 规格、高通携 SD2 重返数据中心 CPU 市场,以及 NVIDIA 的 Bluefield-4,以此作为 CPU 部署未来发展趋势的标志。接下来,我们将探讨 DRAM 短缺对各个数据中心 CPU 细分市场的影响,并展望未来的 CPU 发展趋势,重点介绍将在未来十年塑造 CPU 的关键设计要素。


评论区